Simon Frankau's blog
Ugh. I've always hated the word 'blog'. In any case, this is a chronologically ordered selection of my ramblings.
Playing with curved spaces
I've been playing around trying to understand curved spaces by reinventing the maths involved. The maths and source are up at https://github.com/simon-frankau/curved-spaces/, and if you wait for the giant pile of Rust WASM to download you can also just play with it at https://arbitrary.name/curved-space. I won't write more here, since I documented a fair amount of what I worked through in the README.md
Posted 2024-06-05.
Why Smalltalk is not my favourite programming language
I just read an article that contains a few Alan Kay quotes, and it has reminded me why Alan Kay's mindset has never worked for me. In my teens, I'd read a fair amount of non-specific hype about how Smalltalk was so ahead of its time, and so when I was a university student I went and bought the Smalltalk-80 books to learn more. Sadly, that was before I started writing my book reviews (just over 20 years ago!), so my impertinent opinions were not captured. Instead, I shall write down my views now, that have only solidified over the last couple of decades experience.
I'll start with a couple of horrors that were proudly presented in the books, before moving onto a more philosophical issue.
I can't remember which of the books it was, but there was a code example of a file system written in Smalltalk. This sounded pretty neat! File system code is tricky. Get it wrong, and you'll be corrupting data. You want it to be efficient and performant and reliable, and sitting inside the OS there are usually all kinds of multi-threading issues. Yet it was made to sound straightforward. How could this be? What wonders did Smalltalk provide?
It was about the cheapest, nastiest file system you could imagine. It used block chaining so that each data block contained a pointer to the next block - a scheme I'd only otherwise seen in introductory OS texts because it was so naive. Your data is a power of two in size? It won't neatly fill a set of blocks, then, since each block contains metadata! You want to seek quickly through the file? Bad luck, you need to read all the data from the start! Obviously there's no memory mapping, I doubt there's even caching, and multithreading issues would have been handled by "don't do that".
It felt like there was a fundamental confusion between the simplicity of "a well-designed, simple system" and "hideously inefficient". The ideals of "end-user programming" fall flat in the face of "sometimes you really do need someone to think a little bit and make something good". All of Kay's talk about how we've built rubbish, inefficient computer systems are something I cannot take seriously when this is the example code in the Smalltalk books. The text didn't make excuses for simplified example code or whatever, this was it. I mean, I'm sure Kay could write better code or whatever, but a code example like that's got to be chosen by someone as an exemplar, it tells you something about the language's culture! And it was such a let-down, so Wizard-of-Oz, man-behind-the-curtain.
Some of the most technical content from those books, though, was the description of the Smalltalk-80 implementation. Smalltalk is a wonderfully uniform language, right? Everything's an object, everything's implemented via methods (including loops and conditionals, since chunks of code can also be passed to objects etc.). Even the classes are themselves objects. All pleasantly meta and elegant. And this is all dynamically changeable. You can update methods on core objects, and it will instantly pick up new behaviour. Amazing!
How is this implemented behind the scenes? There's a bytecode interpreter, IIRC (20 years, remember?), and a little compiler down from the Smalltalk to the bytecode. How do we avoid infinite descent when trying to implement the most primitive operations? Well, the compiler understands e.g. booleans, and for the "ifTrue:" and "ifFalse:" methods, it goes and generates the appropriate code. Everything's uniform and all methods overrideable, right? Hahaha. There are special cases hidden behind the scenes that we don't bother the users about, and if they want to dynamically change that behaviour they can't. Simple beats correct.
But does it really matter if you can't dynamically change the behaviour of "true", given that no-one would actually want to do that? This brings me on to the third and more philosophical point: Smalltalk is dishonest about what dynamic change people want, and what dynamic change is helpful.
What most programmers want, most of the time, is a predictable, controlled environment that they can reason about. The biggest trends of the last couple of decades emphasises this: virtualisation and containers allow code to be decoupled from its environment, to have a predictable runtime environment. Source control allows changes to be tracked through time. Both give programmers a chance to reason about the huge pile of state their programs are exposed to. In both cases, people are moving away from wanting to dynamically edit the system they're working on directly and from within that system.
Furthermore, it's rare that people want to dynamically edit everything across the stack. It's rare to want to edit your OS, dev tools, UI system, and app all as a big bundle. It's usually a sign you haven't worked out which layer of abstraction you want to work at (although having said that, tooling exists to allow you to do this in various contexts while maintaining control).
Flexible, script-y, dynamic systems aren't all bad, even if they're usually not my cup of tea. They enable rapid application development, they enable people to solve problems quickly. They're rarely maintainable (and tend to fight with static analyses). I think this is where Smalltalk has its priorities backwards. You want to start with tools that enable comprehension first. Not just "look, I can see the source and edit my window system in real time", but fundamentally source control and virtualisation: Let me see exactly what's changing, and let me debug and work on a system from a system that is not in itself in flux. Build maintainability first.
So, yeah, that's what I found when I dug behind the Smalltalk hype: excessive simplicity and a refusal to engage with the complexity of correct, maintainable and efficient software. Not a lost utopia.
Posted 2024-06-01.
Team Topologies, Agile, Spotify and, well Methodologies
There is an impressive thread by by Patricia Aas, where she gets frustrated by the book Team Topologies, a bunch of Agile-speak, and a talk about the Spotify model. As usual, things like this got me thinking, wanting to write, and what I wanted to write wouldn't fit in the margins of a microblogging service.
I am badly-placed to criticise the Spotify model, and more Agile team structures, since I've not worked in them, or studied them to great depth. I've not read Team Topologies. However, in the great tradition of software development methodologies, whereof one cannot speak, thereof one must have a good go speculating anyway. My claim is that I am attacking methodologies in general, via the medium of the original Spotify model in particular.
It's not all negative, I'll get around to covering what I think is important, too.
Negatives first: When I look at the Spotify model, I see the ossification and idolisation of some rather traditional structures. The "Chapter" looks suspiciously like a dev team, a UX team, etc. The "Squad" looks suspiciously like the people who work together on a feature. "Guild" is Spotify-speak for "WTF? You need a new name for interest groups, a thing that springs up both informally and formally in any org with decent social dynamics?".
Now, the Spotify model evolved, so this is a straw person, but the bit that really sets off warning bells for me is the "Squad". Usually, when a feature needs to get done, someone from each team that needs to be involved gets assigned to it. Maybe, if it's really big, more than one person, but that's also a sign that we might want to take another look at how the work is split up. In other words, we naturally build squads very dynamically and on demand.
So, for all this talk of "agile" behaviour, naming and establishing squads is about reducing dynamicism. Similar pieces of work are routed through the same people. It sounds horrific to work in: Always working in the same narrow domain, and your value to the business being purely defined in terms of the feature area, not what you personally bring. Or maybe it's more dynamic than that, in which case you're running a regular team with funny labels.
The risks are clear: Key person risk and employees getting stuck in a rut. What could be the advantages to such an approach? I think it's supposed to be elimination of the overhead that comes with the dynamicism. Judging by Aas's review, much of the concern is about the overhead of communication. Having pre-established feature groups, with pre-established knowledge and context helps with that, I guess.
Patricia's criticism to me seems too strong: It seems she reads it as "communication is bad", and this is obviously... bad. I read it as "excess communication is bad". If people from opposite ends of your org spend most of their time talking together, maybe your org is badly structured! Good communication is super-important, and necessary. You're going to be spending a lot of time communicating, and badly-structured communications are overwhelming.
So, in the abstract I agree with "reducing communication", but with very strong provisos. Like almost all optimisation problems, the optimal doesn't lie at the extremes. Beyond a certain point, optimising to reduce communication has a much worse effect on the overall system. Having one person and one person alone who knows about a complicated area and refuses to talk about it will minimise communication, but is a very bad situation! When optimising, optimise for the big picture.
The other thing they seem to optimise for is cognitive load, aka people hate working on things they can't fit in their head, or that requires a giant bunch of learning for limited returns, like making a small change. The solution of "divide the world into single-person-load domains and then assign each to a person" is the most simplistic, and a bit crap. It has the downsides mentioned above.
Of course, I'm critiquing my interpretation of a single iteration of a specific methodology, but much of this applies more generally: Team structure methodologies try to crystallise and simplify something dynamic and context dependent. They tend to sell one-size-fits-all solutions to a range of problems, and replace critical thinking with cookie-cutter solutions.
I think this might be what frustrates Aas about Team Topologies. The correct answer to "How should I structure my teams?" is "It depends", and if the book doesn't make this explicit, and concentrate on how to think about the problem, but instead just serves up a mish-mash of examples, well, yes, it's going to be frustrating!
So far, so negative. What do I think the solution is? Number one: Think. Think about your domain, think about the trade-offs, think about the side-effects you might cause. You'll probably need to experiment (or rather, adapt over time), but experimenting on people while they're trying to get work done can be incredibly frustrating, so make sure people are on-board, and make the changes based on their feedback.
There are, though, a couple of timeless factors that come through again and again in organisational design: 1) Conway's Law, 2) It's about people.
Conway's Law, in its many variations, almost sounds like a joke. Yet I've observed its surprising power again and again. Aligning organisational structure with with system structure is an excellent way to optimise communications (and no, you'll never stop comms outside of reporting lines - trying to do so is a bad goal). The best organisational designers I've seen can change the organisational structure to change the associated system, something far deeper than the kinds of changes these methodologies espouse. (This is expensive, risky work, though.)
The other part is that management and leadership is always about people. In this specific context, methodologies tend to treat employees as interchangeable cogs. The organisational structure is designed, and people dropped into roles. This is backwards. If you're hiring exceptional people (you are hiring exceptional people, right?), it's a huge waste not to play to their strengths. In the extreme case, this means creating roles for people. Is this in tension with Conway's Law? Yes. No-one said it'd be easy. I said there aren't cookie-cutter answers, you have to work out what works for your situation.
And briefly, back to the problem of excessive communication, vs. the benefits of communication. This is a holistic problem, and talking about it as a team structure issue misses the big picture. It's also about culture, training, technical design (of both implementation and interfaces), processes, documentation... the works.
Posted 2024-05-24.
Exponential back-off, revisited
The purpose of exponential back-off in retries is almost always to avoid overloading the target. Sometimes it isn't the case - for example excessive retries can drain batteries on the source side. Mostly, though, it's about avoiding an accidental DoS of the target, and so the back-off algorithm should be designed with that in mind.
Digging deeper, there are really two goals: Trading off not overloading the target with retries, versus retrying promptly after the service has come back. Exponential back-off has the nice property of making contact within a multiplicative factor of the outage duration. So, I'm not going to worry too much about prompt reconnection. I'm mostly caring about the "avoid accidental DoS" side of things, which is a real concern in large distributed systems.
Exponential back-off shouldn't be the only line of defense against this internal DoS, either. A comprehensive distributed system architecture should let you rate limit requests and drop traffic so that even in the worst case you can avoid your target getting overloaded.
Anyway, back to the chase: The primary purpose of exponential back-off is to avoid retries overwhelming the target service, prolonging an outage. This is why exponential back-off with jitter is so important. Exponential back-off alone ensures that the average request rate from retries decreases exponentially with time, but if all the clients saw the service go down at the same time, a pure exponential back-off will just lead to increasingly spaced-out huge bursts of traffic. Not helpful. The purpose of jitter is to decrease the peak loads down to a level where the target service can cope.
Therefore, the primary goal of our jittering algorithm should be to decrease the peak load on the target service, while ensuring retries are within exponential bounds (i.e. delays on discovering the service is up are controlled). Yet the common jittering algorithms don't make a decent attempt to meet this goal efficiently!
Let's take an example. We'll assume that all clients see the server go down at the same time - this seems pretty close to a worst case scenario for bursting retries. I'll use com.google.api.client.util.ExponentialBackOff as my implementation. This is not an unusual design, with a default multiplicative backoff factor of 1.5x, +/-50%. The retry pattern looks like this:
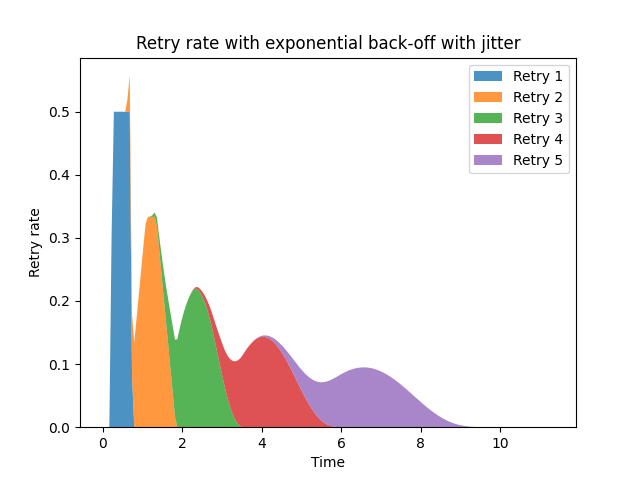
We can see the retries come in waves, with peaks. Each iteration of retries (after the first) forms a bell curve, overlapping the previous retry. These overlapping bell-shaped curves mean that the overall curve is very much not monotonically decreasing. The underlying service may reach a non-overloaded state, and then be pushed back into overload by the next peak.
To simplify things, let's look at Binary Exponential Backoff, as used by Ethernet. This uses discrete timeslots, a multiplicative back-off factor of 2, and a full randomisation range of 0-100% (i.e. retries occur after 0 to 2^n - 1 slots). The use in Ethernet is a bit different, since a single collision in a timeslot leads to failure, while we'd normally assume a service could handle rather more requests per slot, but we can still reuse the algorithm. What we see is this:
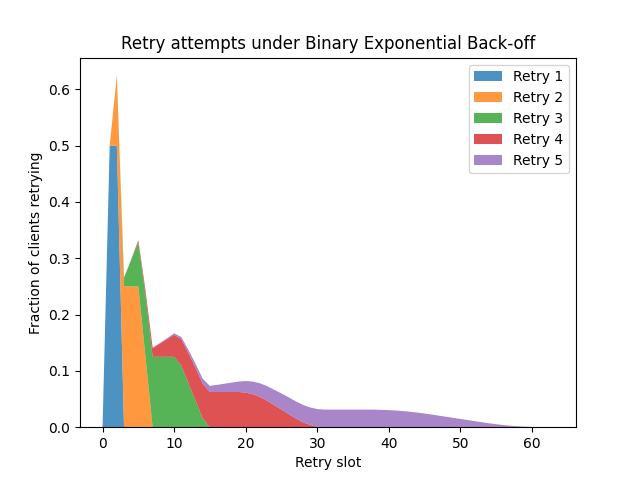
As the randomisation factor is now 0-100%, the distribution smears out much more effectively, with the distribution for each retry having wide, flat peaks. However, we still see local peaks caused by the overlapping generations of retries. What if retries didn't overlap?
This is what I've been thinking about with a modified binary exponential backoff. On the nth retry, delay some time between 0 and 2^n slots before retrying, but if the retry fails, wait until the end of that 2^n slot interval before restarting the timer, rather than doing so immediately. If you do this, the time from initial failure to (n+1)th retry is independent of the time to nth retry, and each retry lives in a separate interval - there are no overlaps. This produces a distribution that looks like this:
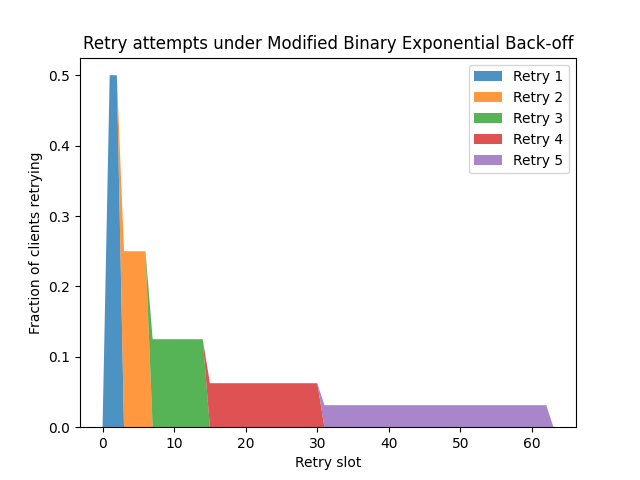
Unsurprisingly, the distribution is more stretched-out, since retry timers are started at the end of intervals, not immediately after a failure. However, the advantage is that, if all clients start retrying at the same time, we have a monotonically decreasing retry rate. It also feels a little fairer: If one client retried a bit earlier in one round due to chance, there's no bias to it retrying earlier in the next round.
We can see the difference between the distributions, and how the modified binary exponential back-off avoids spikes, in the following graph:
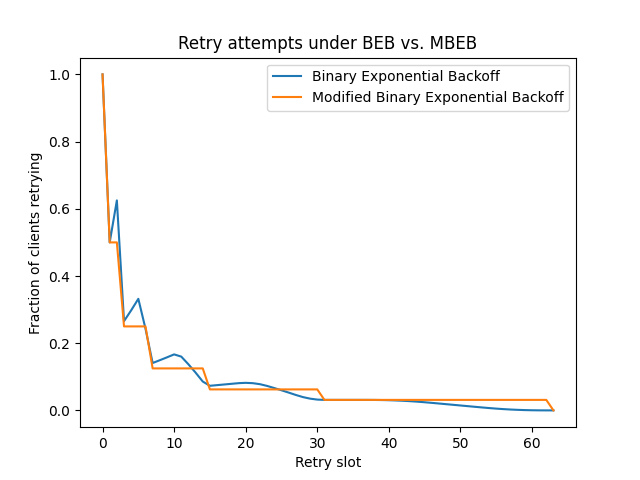
I'll admit that the difference isn't huge, and you can probably do more subtle and clever things than this simple modification. You could analyse the shape of the distribution if you don't assume all clients start retrying at the same time. Yet through all that I think this is a neat little improvement, and I'm rather surprised I've never come across it in regular introductions to exponential back-off.
Posted 2024-05-20.
On Estimates in Software Engineering
@mweagle@hachyderm.io mentioned https://mandymusings.com/posts/cut-scotty-some-slack, which is both fun and full of truth. However, I think of things slightly differently, thus encouraging me to write this.
In the end, the above article still sounds to me of "justifying padded estimates", whereas I want to go with "conservative estimates are a good idea". My view of it comes down to two factors: making sustainable estimates, and making useful estimates.
The "making sustainable estimates" part overlaps with the part in the link about providing slack within the system, but from another angle. Don't get me wrong. I believe in slack. I believe in slack in the sense of queuing systems, and needing less than 100% utilisation if you want queue size to remain bounded. I don't believe in slack-for-slack's sake for estimates.
Instead, I believe in constructing estimates for "doing the job right". Include the time for planning, testing, deploying, documenting, whatever it actually needed to give people what they want, not just the time to code. Estimate the time for the good solution, not the quick solution: the solution where your changes fit the code base without scar tissue, and it doesn't look a sticking plaster of technical debt.
Do this, even if the fix is super-urgent. Especially if the fix is super-urgent. If it's super-urgent, it'll be followed by the next super-urgent request, without time to do the tidying-up in-between. And over time productivity goes down as the accumulated scar tissue makes modifying the code hard. Taking a little more time is faster in the long-run.
That's the "give yourself slack" side of the Scotty article. Then there's the "look like a genius" part - in my terms, make useful estimates. People say "How long do you think it'll take?". They usually mean "If you were setting yourself a deadline, when would it be?".
Let's not try to get this right yet. Let's just start with making an estimate that's about right, on average. When someone asks you how long something's going to take, it's usual to respond with what you think the middling time-to-completion will be. That is, the median (and usually the mode). Except the completion time distribution is going to be skewed. You can't take more than 100% time less than your estimate, but people regularly take more than 100% more than their original estimate if they hit unexpected blocks (and estimates have another weakness in that they usually assume a lack of unknown unknowns). In terms of statistics, the distribution is skewed. If you base estimates on the median, you'll be underestimating the mean.
Except... people don't really want the median or even the mean. That's the normal-case estimate. If you give people the median, you're giving them an estimate you're going to exceed half the time. Very unimpressive. The mean isn't going to be a whole lot better. And, if you miss, given the skew, you'll likely miss by a fair amount. People want to know when you'll probably be done by. Really, you want a percentile. If you can give people the 90th percentile, you're giving them an estimate that's achievable 90% of the time. Let's go for that.
By the time you've gone for a high percentile estimate, given a plan for doing a proper job and the skew inherent in the distribution, it'll feel a lot like padding the estimate. While the Scotty discussion is entertaining, when it comes to producing a "padded" estimate that can be quantitatively based and used by the most scrupulously honest, I prefer my approach. I'm probably biased. :)
Posted 2024-04-07.
More physics: Action and Lagrange
My last post on physics, about forces, momentum and energy, left a few open questions that I didn't want to dive into, lest I never finish the post. One that seemed obvious to me was "if you get momentum and energy by integrating force over time and distance, what happens if you integrate over both?". I carefully avoided researching this to avoid going down a rabbit hole.
A more pressing gap was Lagrangians, and the "principle of least action". Lots of university-level discussions of physics use Lagrangians, and if I wanted to push any further I thought I really needed to understand how they work.
The TL;DR of the principle of least action is that there is a function of the paths of objects in the system over time, called the "action", and the path actually taken by the system is the minimum of this function. The paths taken, somehow know the route to minimise this quantity. How mysterious!
The action itself is an integral over time of a function of position and time. That function is the fabled "Lagrangian" (or rather, a Lagrangian is a generalisation of this function). The Lagrangian for the basic case is a function of the system's energy. That is, the action is an integral of energy over time, but it can also be calculated as an integral of momentum over the path: It is precisely that integral of force over time and space that I was wondering about earlier!
So, that's the principle of least action, but why is it equivalent to Newton's equations of motion? Awesomely, there's a Feynman Lecture on Physics on this specific topic - I never really got on that well with these lectures (his view of physics somehow doesn't resonate with me, but I found Penrose's The Road to Reality very intuitive), but I found this chapter very accessible.
Why does the Principle of Least Action work? Well, the mysterious "whole path is minimised" property is actually just a way of saying that every point along the path is locally optimised. The solution is not necessarily a global minimum, or even just a minimum, it's a local extremum along the route. For it to be a local extremum, small pertubations must not change the integral. In some sense, the local derivative of the action with respect to tweaking the path must be zero. And the function that describes how the action changes with path tweaks is an equation that is zero when Newton's laws of motion are satisfied! (Roughly.)
Anyway, go read the original for details. It includes an introduction to the calculus of variations, which is how you optimise along paths, and is a very neat tool. He provides a muuuuch more rigorous explanation of it all than I do (though still physicist-level rigour :p ).
The Principle of Least Action seems a weird way to understand Newtonian Physics to me. As a simulation-minded kind of person, a Newtonian universe would clearly follow his laws of motion step-by-step, rather than be the solution to an integral minimisation problem. Practically, using a Lagrangian has some advantages. It allows you to constrain the motion of a system conveniently, with the aid of Lagrange multipliers. So, it's just a convenient calculation tool, right?
Yet this "solution of path integrals" approach seems meaningful in other areas of physics. In optics, light takes the minimum time route between points. This minimum time route, as a local minimum, is a stationary point in the phase of the light at the destination - in other words, it's a point of constructive interference as a wave. Quantum mechanics takes this further, with the probability of a particle being at a point being based on an integral over all the possible paths.
What I felt was a computational convenience for the "real" equations of motion might in some sense be more physically meaningful than those "real" equations!
Around this point, I had another realisation, and it's about there I got stuck.
Going back to Newtonian mechanics, and extending it in the direction of special relativity, the action is an integral of force over time and space... but in special relativity there is only space-time! In special relativity, momentum and energy are the space and time components of momenergy. Perhaps action in SR can be viewed as something else? Some kind of thing where 4-forces get integrated to momenergy, and momenergy gets integrated to whatever the SR version of action is?
I tried to work out the maths behind how this would work in SR, and... failed. I tried a few approaches to generalise the action in a way that becomes Newtonian at low speeds, but couldn't find the right way to break into it, and then got stuck.
Fortunately, the Wikipedia Relativistic Lagrangian mechanics page exists, and does the work for me. Fascinatingly, it's the path that minimises the proper time of the object. I was hoping it'd come out as something like this, and apparently it does!
I can also see this as a step towards general relativity, which I must admit I don't have a mathematical understanding of. This "shortest path in spacetime, as determined by proper time" feels very metric-like, and you can see how you'd end up dropping the forces and just end up with this metric that corresponds to curved space-time. Yet more fun!
And there's some similarity between how I find the principle of least action a weird way to express e.g. Newtonian mechanics, and how I see people viewing curved space-time as a special thing for GR. Reading Penrose's Road to Reality (see above), it mentions that Newtonian gravity can also be modelled through curved space-time. I believe optics can also be handled be distorting space - assume light travels at a constant speed, and insert more space into the regions where light is travelling more slowly (lens material etc.), although handling the discontinuities is an exercise for the reader.
So this seems to be leading me to try to think about GR, but that's a whole different post!
Posted 2024-04-06.
More Crochet
Having crocheted a cat, I decided to keep going. Way back when, I crocheted a Groot. What I didn't mention is that I took it into work as a replacement for a previous woollen Groot that was stolen, and it, too, was stolen. Boo.
So, I finally got around to making another. Interestingly, it was a lot quicker to produce this one, so clearly the practice has been effective. The most tedious part was certainly sewing it all together. This one is not going into the office.

After that, as I mentioned in my book review, I wanted to try some different techniques, as opposed to just amigurumi. I ended up making a small blanket from the infamous granny squares. The colours of yarn I had were somewhat limited, so I decided to lean into a full '70s look, with orange and green. It's horrific.
The whole thing was a huge learning experience. After making the first few squares from a somewhat vague pattern in a book, my sibling pointed out that I should be crocheting into the holes, not the loops - very different from amigurumi. I also discovered that the orange and green wools weren't quite the same weight, so that the orange and green squares were noticably different sizes. The mixed-colour ones were pretty uniform, somewhere in the middle. Indeed, the mixed-colour squares were easier to produce, as changing colour made it rather easier to see what's going on.
The book said that the two options for combining individual squares into an overall blanket were to crochet them together as you go, or stitch them together afterwards. I opted for the first, and I think this was a mistake. I think stitching allows for a better join, and it makes creating the invidiual squares rather faster, since you're not trying to work between squares. Still, even with that impediment, I was impressed with how quickly you can make progress. Trebles cover the ground a lot more quickly than doubles, and with a heftier yarn you could probably make a decent larger, holey blanket in a reasonable amount of time.
One thing that was utterly new to me was blocking. The mini-blanket was pretty wonky by the time I was done, and the squares were of varying sizes. There wasn't a huge amount that could be done about the square sizes beyond some mild stretching, but it could at least be made a bit flatter and even. For synthetic yarns (I don't want to waste decent natural wool on my beginner's experiments!), the Internet recommends steaming with an iron; I tried that, it seemed to work ok.
So now I have a small and weird mini-blanket that I have no idea what to do with!

Posted 2024-03-13.
Determinism is awesome
I saw a post on Mastodon saying "the older i get, the more i realize that I/O is at the bottom of literally every engineering annoyance i deal with. the further i can push I/O to the edge of my program state, the better.". This is something I agree with, and it got me thinking about what it is that I really appreciate.
Pulling the I/O out has several advantages. I/O is great at generating errors, so it can help lump all the error handling together, and you can avoid having to handle error propagation throughout the whole stack of code. In the opposite direction, it makes mocking for testing easier, since you don't have to dependency-inject a mock right into the core of your code. And pulling I/O out helps make your core code deterministic.
To elaborate on that final point, I/O is great at not behaving the same every time. Doing I/O interacts with a giant, hidden pile of state. In contrast, pure-functional-style code that does no I/O has a decent chance of working the same every time.
For me, based on my early career, determinism is big win. I spent most of a decade working on pure functional style systems - a quant (financial maths) library, and a DSL (domain-specific language) written in Haskell. In these systems, you send in some input, and get some output. The output is determined solely by the input, and the output is the only thing you care about. Testing is just sending in input and checking the output, and if you provide the ability to record input and outputs in prod you can trivially debug offline. No heisenbugs or schrödinbugs. I find fixing bugs to be one of the most unpredictably time consuming parts of development, and with deterministic code life is good (usually - see later).
(I'm going to play a little fast and loose with terminology by conflating pure functional behaviour with deterministic code. Sorry. I'm sure you'll work it out.)
I later spent a couple of years working on an algorithmic trading system, and while it did plenty of I/O, the core algos were deliberately in a pure functional style, with very explicit inputs and outputs. The huge advantage of that is that exactly the same code would run in exactly the same way against live markets and against recorded data for (back) testing. I've heard similar approaches used in computer games.
From there, I moved onto large-scale distributed systems. There's no hiding the I/O there. Yet even there, you do what you can to regain control. Making the I/O into uniform RPCs allows you to apply standard patterns. Standardise the error handling via e.g. making things idempotent and limiting error handling logic to try again/give up. Build observability tooling, and use heavy logging to catch the inputs and outputs you can. If you squint, you can try to design each RPC handler as a pure function. It won't be perfect, but you can push to that style as much as possible.
If you extend your use of determinism, you get nice extras. If your top-level system that behaves in a pure functional way is made out of pure functional components, you get compositionality: Each sub-component can be analysed separately in terms of input and output, and you can take an easy, reductionistic approach to debugging, dividing and conquering. Refactoring can be achieved safely through local changes, and tests can be arranged hierarchically. This is roughly what you get with the encapsulation of OO and associated unit tests. From another angle, if you can fully enumerate intermediate state, you can probably checkpoint your code.
I/O is a key determinism-killer, but it's not the only one. Some I/O is non-obvious. Caring about the current time introduces non-determinism. Multi-threading is well-known for creating non-determinism, and any multi-threaded code needs a clear model as to why it's going to behave. "Human thinks hard" won't cut it. Using real random numbers obviously creates non-determinism. Outside of cryptography, you almost always actually want pseudo-random numbers, for reproducability. And perhaps most frustrating of all, memory-unsafety bugs create non-determinism. A particularly malicious, hard-to-debug form of non-determinism with spooky-action-at-a-distance, the damage turning up far away and much later than where it was created.
So, finally, a couples of stories of unexpected non-determinism cropping up in our theoretically-pure-functional quant library. We had some heavy models that got distributed out onto a compute grid. The price for a particular complicated product would jump around, given the same input, maybe something to do with which machine it was running on.
Further investigation revealed the product in question relied on a particularly heavyweight calibration stage. The calibrator, relying on numerical methods and probably some not great market data, was not expected to always converge, and if it didn't, it would fall back to a simpler model. It would do so, non-deterministically.
The fallback code looked something like "try { calibrate(); } catch (...) { fallback_calibrate(); }". The blanket exception-catcher turned out to be catching a memory allocation failure exception (this was a heavy calculation!). In other words, the profit-and-loss for this particular trade would be determined by how much RAM the machine had!
The reason given sounded plausible: Surely you'd prefer to get some price out, rather than have your trading book non-deterministically fail to price? It turns out exotic derivatives traders are a detail-oriented bunch, and no, they would rather have something clearly and explicitly error than just randomly change in price, unannounced, in a way that slowly drives you mad (and screws up finite-difference-based risk calculations). Exotics traders have something of the dev mindset.
That one was interesting, and gave me some understanding of priorities, but I also saw another, which I found more depressing. A good quant understands finance, stochastic calculus, numerical methods and software engineering. In practice, most are weak at software engineering (so they employ quant-devs - hi!), and they pick up finance on the job over a number of years. You want the core competencies of stochastic calculus and numerical methods. You usually get just the stochastic calculus. Hence this story.
All this took place before Cloud was commonplace, and even then for the level of utilisation it makes sense to have your own hardware. So, we had a bunch of machines to calculate heavyweight models on. They were Intel machines, but AMD had just started producing some incredibly good price/performance machines, so we bought a bunch. And... a bunch of trades priced differently on them!
Investigation followed. I forget the exact outcome, but it hinged on the way that Intel FPUs have 80-bit FP registers, but values get stored in memory as 64-bit values (I think you can force the internal representation down to 64 bits, too, but - hey! - free precision!). For whatever reason, AMD did not work identically - whether it was just 64-bits internally, or went through a different code path with CPU-specific optimisations that dumped values via RAM, I forget. Maybe it didn't need to spill values to RAM. The upshot was that some intermediate values were truncated from 80 bits to 64 on one architecture and not the other.
There was much internal hand-wringing about all this - about buying machines without sufficient testing, about bad hardware and bad compilers and all the rest of it. No-one seemed to see the headline that I did: If your code produces wildly different results with 64-bit and 80-bit precision (and you didn't know this already because you'd designed it that way), your code is numerically unstable, and the numbers that are coming out of it are largely noise. You have discovered a bug. Be grateful for it, fix the bug, and don't blame the messenger.
So, uh, yeah, the compiler and microarchitecture can be a source of unobvious non-determinism too, if you try hard enough!
I love determinism.
Posted 2024-03-07.
Trashy Movies I Have Recently Watched
My health has been on a pleasant upward trend since the New Year, putting me at a level where I can watch, concentrate on, and enjoy films, but for a while not do much more. Between that and recently subscribing to Disney+, which seems to have a rather better selection of films than Netflix now, that's what I did.
Since I watched the films on my own, and had no-one to talk to them about, and like to mull them over, you, dear Internet, are getting my Thoughts.
Speed
Likely the least bad film I've seen containing Sandra Bullock. OTOH, I saw Speed 2: Cruise Control years ago, and that was likely the worst Sandra Bullock film I've seen, so I guess it balances out.It's a pleasantly frothy action movie. I suppose between the crazy plotline and overall lightness of the film, it gets its place in the canon of action films despite otherwise being rather mediocre!
Keanu's character is strongly signalled to be brilliant if headstrong (and heroic, obvs.), with him making several key deductions on the fly in what should be an impressive lightbulb way. Yet, if you look at his actions closely, many of them are nicely dumb, serving no purpose other than to complicate the plot and drive it along. As a very simple example, if you think the baddie is hiding in a lift, disable the lift's motor first before trying to poke around!
On the other hand, the bomber character creates well-planned, possibly over-complicated schemes and clearly has an extreme chip on his shoulder, but the background and motivation are hugely under-developed. Beyond the surface detail, he's a cipher. I guess that's appropriate for an action movie as light and fluffy as the Los Angeles it's set in (with the film culminating in Hollywood!).
Speaking of the film's ending, it's got the worst final lines of any film I've ever seen, namely: Jack: I have to warn you, I've heard relationships based on intense experiences never work. Annie: OK. We'll have to base it on sex then. Jack: Whatever you say, ma'am., which I think is followed by a bystander unironically saying "How romantic".
Taken
Another dumb action film, whose fame derives from That Line, which has found its way into a million memes. At the opposite end of the spectrum from Speed, the action takes place in a deeply unpleasant underworld. If you disengage your brain, it's got the fun of the mindless violence you expect, where the protagonist is a super-hero destroying dozens of ne'er-do-wells and coming out basically unscatched.
Brain engaged, it's pretty horrible. Xenophobic and brutal, any and all actions justified by the protagonist's sense of righteousness.
Specifically the plot centres around a man who worked for the CIA. Someone who's job is to apply large amounts of clandestine violence around the world in the name of the USA. He's seen the real world, it's a horrible, horrible place, and only killing lots of foreigners will keep it safe.
All this killing left little time for his wife, who divorced him, and married a multimillionaire businessman (who is soft, and has a pleasant life of not meeting the most evil scum in the world and killing them), taking their daughter with them.
He is devoted to his daughter. Let me rephrase. He's paranoid and controlling. He knows the evils of the world, and it's a miracle that she's nearly reached adulthood without getting embroiled in a plotline from 24. She wants to visit Paris, which is outside the US and therefore dangerous, and so he refuses until his arm is twisted and he's lied to about the itinerary and reluctantly he gives permission for her to go.
So, of course, within hours of landing in Paris she is kidnapped by Albanian gangsters. Not because she's connected to a CIA spook or anything like that, no, just purely random because Albanian gangsters are kidnapping so many young American tourists into a world of forced drugs and prostitution. It really is like that, you know, I've been to Paris.
At this stage, thanks to the conveniently-timed phone call of the well-known meme, our protagonist knows to hop on a plane to Europe and start killing large numbers of people until he finds his daughter. Obviously you can't trust the French intelligence services, because they're lazy and corrupt.
His daughter is such a sparkling prize that she is put up at a secret auction behind the scenes of a party for the social elite. All very QAnon conspiracy. (I'd like to call it massively far-fetched, but, er, Epstein, I guess.)
And she's bought by a middle-eastern sheikh. Of course. Not enough stereotypes otherwise. He fights them. They have curvy knives.
Just to make sure you understand that he's just acting to protect what's his, not out of any higher moral calling, he does shoot an innocent woman just to make a point.
So, yeah, this is in many ways a really grim movie. The world outside of the US is horrible and dangerous. All of it. And the only solution is massive, unrestrained violence.
Free Guy
While Taken is a philosophical black hole dressed up as a mindless thriller, Free Guy is very nearly something interesting dressed up as a kind of comedy.
The plot centres around Guy, an AI NPC in a MMO game who doesn't realise what he is. The game has advanced AI in it and apparently he's become sentient. He works out how to act like a player character, and causes much confusion.
The game is clearly a rip-off of GTA Online. Liberty City has become Free City. It tries hard to capture the cheesiness and posturing of online gaming culture and personalities. As in-game events progress, there are occasional vox pops from streamers, an update on newspaper headlines spinning onscreen in black-and-white films.
There are some big philosophical questions brought up here by the way that we apparently created the first sentient artificial life form in order to be the constant victim of virtual crimes, for the entertainment of humans. This is resolved by the fact that the NPCs are very cheery and seem to enjoy their life in Free City. It's like a reverse The Matrix: Humans build an artificial dystopia for AIs, that they enjoy. One must imagine Sisyphus programmed to be happy, I guess.It's entertaining, but the thought-provoking side goes absolutely nowhere, it resorts to a standard movie formula, and wedges in a romantic sub-plot at the last minute, because of course it does. Of these three movies, it is perhaps the one that I find least irritating. Given what the Barbie film did about plastic dolls, there was clearly a lost opportunity to go a bit deeper while remaining entertaining, but as shallow fun it's fun.
Bonus #1: The Orville
Not a film, and I'm way behind the curve, but I've finally started watching The Orville and am enjoying it.
Having worked my way through Star Trek: The Next Generation and Lower Decks, I found myself out of Trek I enjoyed. I never got the hang of Voyager, Deep Space Nine is insufficiently utopian, and Enterprise suffers from trying to make the characters act so much like cowboys that the crew of the TOS seem like professionals in comparison.
The Orville makes a surprisingly good substitute. Things are different enough to make an interesting compare-and-contrast, but similar enough that you can feel at home pretty quickly. The optimism of the Star Trek universe remains. The crew aren't quite professional, but are doing their best, almost like the opposite of Enterprise's professional-acting crew that make bad decisions.
As a deliberate comedy, it has the opportunity to push things further than TNG, which sometimes makes for more interesting sci-fi. TNG was always a little bit silly, needing someone like Patrick Stewart to give the thing gravitas, and the deliberate elements of levity were always a little bit eye-roll inducing. As with Lower Decks, just plain embracing the humour works very effectively. So, yeah, so far, I'm enjoying it lots.
Bonus #2: Tenet
While I'm writing about movies and all that, I've been reminded of another film I watched towards the end of last year: Tenet. I vaguely remembered reviewers thinking it muddled and confusing, and having felt that Inception was a mess of a film that was far too proud of itself, I left Tenet alone for a long time.
As it is, I thought Tenet was one of the freshest and most innovative takes on time-travel I've seen in a long, long time. Pretty much enough to stop me saying "THAT'S NOT HOW ENTROPY WORKS" (it isn't, though). As to the confusion, I thought the film was quite successful at building up the sci-fi concepts incrementally, so that you're not hit with the full idea load all at once, as well as successfully keeping the suspense going.
I wish I'd twigged the sator square connection from the film's title before seeing it, though!
Due to the way the time-travel is constructed, it's firmly in the "the future is fixed" camp of time-travel, which I always tend to find a little depressing. However, I'm willing to forgive that because it's so much conceptual fun. On the other hand, maybe I'm getting old, but I did feel the violence was somewhat excessive, and a bit too gritty for my liking. Kenneth Branagh makes an exceptionally unpleasant baddy. Well done, I guess?! Conceptually, though, I was thinking about it for days.
Posted 2024-02-29.
More crochet, cat edition
Some time back (2019, according to my blog) I did some crochet. Some time afterwards, I received a crochet kit, for a little chubby cat. Somehow, I never found the right combination of time and effort to work on it.
Until now.
The kit was a very funny one - I'm totally unsure what they think the target market is. It provides everything you need - including crochet hook and needle, so at that level it's signalling it's for someone with no crochet kit, presumably someone who's never done crochet before. At the same time, this is really not a kit for an absolute beginner. The instructions are pretty bare, the yarn provided is high-quality, fine wool, that you're supposed to use two strands of at a time, which is a mild pain. The design requires you to change colour (read "faff") twice a round. In other words, it's trickier than the projects I've worked on before.
I got there in the end. The tail is way more raggedy than I'd like, but after the amount of undoing-and-redoing I'd done by that point, I thought I'd let it stand.
At this point, it looked something like this:

The fun thing about this kit, though, was because it's made of nice wool, is that it recommends that you can wash the result at 40 degrees to make it go all fluffy. So that's what I did, and this is the result:

My family seem rather happy with the result. I can see a few more crochet projects on the horizon.
Posted 2024-02-26.
Playing guitar is like sailing
I think this is a somewhat personal simile, but bear with me: Playing the guitar is more like sailing than playing the piano.
As I attempt to pull myself (well, be assisted) out of a health low, I've been looking for activities I enjoy, to fill the gaps in my life previously occupied by "being ill". I want to get back into music theory, as you can see from a post or two back, and I'm also looking at trying to learn a little more rock guitar, something I've been a time-to-time novice at for many years. I don't expect to get good, just enjoy it.
(Why rock guitar? I've never been into classic rock, Led Zeppelin for example leaves me absolutely cold. On the other hand, much of the indie/alt rock I love, like Smashing Pumpkins, seems to build more on that style than others. For me, power chords are a better starting point than more classical chords.)
My previous musical experience is playing the piano. I was pretty good at it, got up to Grade 7 ABRSM, even if I'm extremely rusty now. The piano "interface" is extremely well-defined. You make music by pressing and releasing the keys at the appropriate time, with appropriate force/speed. Slightly fancier than the harpsichord (no volume control), but clinical enough that my entire playing style could be captured in a basic MIDI file.
It's not unlike using a computer, where the interface is through a small set of devices, discrete and digitised.
I learnt to sail the year before the pandemic. My initial assumption was that it was kind of similar. Sitting in the boat, holding the tiller and main sheet (rope) to control the sail, I thought that was the interface. Early on, I was surprised to see the instructor help the boom across during a tack by pushing it with their hand. It seemed like cheating.
Over time, I realised how wrong my initial impression was. I moved from learning in a Bosun, which can happily seat four, to playing around in a single-handed Pico. Weight distribution is hugely important - where you sit, and how you lean, are vitally important. I was taught to roll tack - a fun technique I never really got the hang of - which relies on you moving your weight around very dynamically to tack efficiently. I also learnt about adjusting the vang/kicker, the centreboard when going down-wind, and other miscellaneous adjustments.
In short, the interface with the boat is actually whatever it takes to get it going where you want it to go. It's a wide, subtle and flexible interface.
Electric guitar is like this. It's not just a matter of pressing down some frets and striking some strings. I had not really twigged all the techniques for muting, damping and stopping strings, quite how numerous the variations in how how you strike the strings are, hammer-ons, pull-offs, bends and slides, variant tunings, all the various playing techniques, before you get on to different guitar types, knob settings, amps and effects. Let alone "prepared guitar" a la Sonic Youth. With electric guitar, whatever you do is valid to produce the sound you want.
In many ways, I think this "insight" will seem incredibly shallow to most, and is perhaps more of an insight into how I think about things than the things themselves. Despite that, it has had a significant effect on how I'm approaching learning the guitar!
Posted 2024-01-26.
A small addendum on Henry Kissinger
Something I read has mad me think a little more about Henry Kissinger, beyond what I wrote before.
First, a side-story (I don't think it quite classes as an anecdote). Back at uni, I was searching for the university Go society (which I eventually did find, becoming a bit of an avid player for a few years), but instead found the DipSoc: the Diplomacy Society. I'd assumed from the name it was like a Model United Nations, or something, but Diplomacy is like a dice-free version of Risk. Totally deterministic, the way the game plays out comes from sneaking off and chatting with the other players, forming alliances, betraying, etc.
I only played one game, on that evening, before finding Go soc instead, but I did find it fascinating - very practical experience in game theory and negotiations! Anyway, in one round I had a spare army, and thought "might as well use it", and just chucked it in a random direction against a not-particularly-hostile neighbour, expecting them to be defending. They were defending, but after that, they did not trust me and my game suffered. In retrospect, it was an obvious dumb move, burning trust for no good reason.
Anyway, back to the present. I'm a fan of Sam Freedman, and a subscriber to his Substack. A nice bonus is it includes interesting articles by his father, Lawrence Freedman ("Emeritus Professor of War Studies at King's College London"), and recently he'd interviewed Joseph Nye Jr. who, among many other things in his career, coined the term "Soft Power".
Nye defines soft power as having other countries work in your favour because of attraction, as opposed to military or economic force. He's obviously not so naive as to believe that this alone is sufficient - he calls effective use of soft and hard power combined as "Smart Power", which is what he advocates.
I highly recommend the article if you don't know much in the area, but I also think it's a nice piece of vocabulary to put around Kissinger's approach. He was so focused on the use of hard power that he actively destroyed the US's soft power. Nye invented the term "soft power" to describe the US's advantage - that while the USSR held countries behind the Iron Curtain by force, Western European countries were attracted to the US. To burn such a distinctive advantage seems most unwise.
In some ways, it feels like Kissinger's career is my one move in Diplomacy, writ large: I guess I'll take this hard power move here, with no thought of how it affects trust.
Posted 2024-01-19.
Music theory for dummies: O Come, O Come, Emmanuel
I've been wanting to get back into trying to understand music theory for a while, and have finally taken the opportunity to spend ten minutes to dig into something that's been on the back of my mind for a long time: Why is it I like the tune to Oh Come, Oh Come, Emmanuel so much?
I guess I only think about this for a small fraction of the year, with it being a Christmas song. Lyrically, it's probably a bit of a political mess right now, but I'm focussing on the melody.
The obvious answer is "Almost every Christmas carol is in a jolly major key, and this hymn is clearly something more minor", but it sounds a little funkier than simply being in a minor key. I took a look at the score.
Looked at through the lens of classical music theory, it's pretty close to a minor key - perhaps fitting into what's allowed by a melodic minor scale. The minor-ness is announced right at the start, with the initial interval going from 1 to a flattened 3. So far, so minor.
What is interesting, though, is that some way into the tune we find out that the sevenths are not raised. This is not the harmonic minor. Maybe we can squint and call it the melodic minor? (If I play the piece with raised sevenths, making it a conventional minor scale, it's much less interesting.)
However, this isn't the only way to look at it. Not everything has to be tonal major/minor. The alternative is to realise that the melody is played with the notes of the major scale, only centred on the third note of the major scale. Or, in the framework of musical modes, it's in the Aeolian mode (which I now discover is also known as the natural minor!).
So, there we go. I think I like the way it's in the Aeloian mode, and that's nice and unusual in the world of cheerful Christmas songs.
Posted 2024-01-15.
What works in interactive fiction?
From time to time I'll get the urge to play some "interactive fiction" - known back in the day as text adventures, with the big names being Infocom and (in the UK) Magnetic Scrolls. I recently had that feeling. Reading up on a bunch of old ZX Spectrum computer games, I wanted to play something from that era. Level 9 had a reputation as a major publisher during that period, so I thought I'd try one of theirs.
I thought I'd try the classic Gnome Ranger. I fired it up, explored for a little bit, quite enjoying the start, and then got solidly stuck. I got the sense that this wasn't for me, and wasn't heavily invested in it, so rather than persevere I took a look at a walkthrough. The given solution left me glad that hadn't tried to put the effort in to find it.
This lead me to thinking about what I like in text adventures, and what doesn't work for me, since the difference seems incredibly stark.
I think the key concept is that a text adventure needs to be "goal-oriented": There's something you're trying to achieve, and the actions you take should be relevant to achieving that goal. At the simplest level, games like Advent and The Guild of Thieves have you collecting treasure: a simple, obvious goal. Others, like Christminster, Trinity and Jinxster (all of which I highly rate) have some kind of higher goal, and your efforts are directed by that. Both The Pawn and Gnome Ranger seem to dump you in a landscape to wander around, trying unmotivated things until something happens.
The critically-acclaimed game Curses is also a little of the "wander around, trying things" persuasion, but it demonstrates another aspect Gnome Ranger lacks: a structure to help you understand if you're on-track. In Curses, you might come across an interesting situation, play around with it, and get the gist of whether you're attempting what was intended, and whether it's helpful. Gnome Ranger leaves you wondering, trying all the actions you can think of to provoke some reaction, rather than progress logically.
The third thing that made Gnome Ranger not for me were the non-player characters (NPCs). Pretending there are other sentient beings in a game is tough, doing it right is hard, and the illusion is easily broken. So, nobody really does it right. In practice, NPCs are automata that you can get information from, that you can do things to, or can do things to you. Their purpose is highly ambiguous; whereas it's pretty clear what a lamp is for, what are you supposed to do with a nymph? Oh, and they have an annoying habit of wandering off, because aimless wandering is apparently realism.
Inevitably, though, in an NPC-heavy game, you'll end up treating NPCs as your personal robots. There'll be some command of the form "walrus, n, n, pull lever, e, get gem, w, s, s, give gem to me", which I feel is both a soul-less puzzle and an excellent way to break any suspension of disbelief you might have managed. In short, NPC-heavy games leave me cold: they weaken the focus, weaken the atmosphere, and encourage lazy puzzles.
NPCs aren't inherently a disaster, they just need to be carefully managed. Non-sentient, or at least non-verbal NPCs can have a clear purpose, and avoid the complexities of following commands or answering questions. A magpie that steals shiny things can form the basis for a puzzle with no complications. Well-defined roles can also constrain expectations and signal plot. Bar staff or ticket inspectors, focused on their job and nothing more, can work well. Open-endedness is a problem.
So, there we go, we now have Simon's three rules for building good interactive fiction: Ensure the player is motivated by an overall goal, provide logical puzzles that give clear feedback along the way, and ensure your NPCs are well-defined.
Posted 2024-01-06.
Henry Kissinger
Henry Kissinger is dead. This has lead me to have another think about why I disliked him so much. I'm writing my thoughts down in an attempt to coordinate them.
I want to avoid the simplistic approach of military stuff kills a lot of people, he made that happen, he's bad. In the middle of the Cold War, things were a bit more complicated, and I don't have the analytical powers to look at history and determine what would have happened otherwise.
I wish I had. If I could know the outcomes of a non-Kissinger approach, I could have much stronger convictions of my belief. Otherwise, all I can do is criticise the overall approach, the internal logic, and the apparent effectiveness.
And I'm not a real historian. My half-assed analysis may actually be totally wrong. I guess if I write it down people can tell me where the biggest mistakes are.
Kissinger apparently didn't like the label of "Realpolitik". However, from his actions it's clear that in the fight against communism he either didn't actually value liberal democracy, or took such a "the ends justify the means" approach to render it meaningless.
He would support authoritarians and despots in order to undermine communists. This had a number of problems. It didn't advance the cause of liberal democrary, only do its best to stay communism. It meant that several horrible regimes could be seen as being due to, and supported by the US. It destroyed trust, and made it look like the US didn't really stand for anything. It probably made communism look that bit more attactive for a small, poor country, if the alternative was a fascist puppet government installed by the US.
In short, there are people who pride themselvess on making difficult decisions, and Kissinger was one of those. "Difficult decisions" really mean decisions that's going to hurt someone (generally not the decider) and likely be unpopular.
The thing about making difficult decisions, is they still need to be good decisions. If you make difficult, bad decisions, you're just hurting people. Some people seem to think difficult decisions have intrinsic value. They don't. They're only good if they're good.
Strategically, they don't look great. If you want to keep the US democratic via some kind of domino theory, having a bunch of authoritarians that you support and a bunch of countries thinking you'll bomb or coup them on the thinnest pre-text is probably not a great place to be.
Tactically? Well, despite all the bombing in Vietnam, Cambodia and Laos, they lost that war. And Cambodia got Khmer Rouge. Maybe things would look worse in an alternate timeline, but that looks pretty unsuccessful.
The world is not a scientific experiment, we can't know how it'd have gone otherwise. Yet despite the failures, despite supporting evil regimes coming back to bite, the conviction remained that killing lots of people is the best way forward.
In some ways, he was an incredibly Nixon advisor. Watergate was a stupid, bad idea, but it was sneaky and tricky, so they did it anyway. Secretly recording conversations in the White House? Might well come back to bite him, but it's sneaky, so let's do it.
Kissinger was so enthralled with the idea of doing what was necessary, that he did the unnecessary. And millions died.
Posted 2023-12-01.
Ramblings on the philosophy of mathematics
Some time ago I read a somewhat informal paper that was basically an ode to equivalence classes. Equivalence classes, isomorphisms, homeomorphisms and similar abound. A lot of maths is going "this thing is shaped like this other thing".
Coming at it another way, maths is about the study of interesting patterns and structures. The interesting ones are the ones that keep cropping up. While you might define what a group is through a set of axioms, a group is really the name given to a set of patterns that kept occurring, and the generalisation of them.
This is all both anti-Bourbakist and in tune with the way maths really operates. Solvable groups pre-existed groups as Galois invented them for Galois theory, to say nothing of how people managed arithmetic for millennia before it was axiomatised.
Switching over to computer science for a moment, this is pretty much what's at the root of what's wrong with almost every monad tutorial. The stereotypical tutorial tries to explain what a monad is, in its generality, first. It would be so much more sensible to explain how you might want to build combinators to handle list comprehensions, state readers and writers, errors, I/O etc., and then point out how they all follow the same pattern, and that pattern is what a monad is, and how it can then be formalised.
Coming back to the realm of maths, the fact that these are repeating patterns that occur in different contexts mean that there's no single, true formalisation. You can build the natural numbers from set theory, or zero and a successor function, or lambda calculus terms, or whatever. They're all equivalent, and none is innately better.
Getting more metaphysical, if you see a system, you might ask what it's embedded in. If you can't tell from the inside, it's pretty much embedded in all the possibilities, and none. Putting it another way, engaging with a question that worries some people far more than it's worth thinking about (one generation via The Matrix, another via AGI over-analysis): The question "Are we all in a simulation?" is essentially meaningless, another Gödellian "undecidable inside the system" question.
I rather like maths giving me an excuse to not engage with such questions. I get to spend more time thinking about the lovely interesting patterns.
Posted 2023-11-23.
The Internet's Memory and Nix's Logo
Sometimes, the longevity of the Internet's memory (or lack thereof). I have a soft spot for the Nix logo, and occasionally see it crop up in weirdly hacked-up ways, which'll send me down memory lane.
The Internet will very clearly tell you the logo was designed by Tim Cuthbertson. What the internet isn't so good at is telling you is that I designed the previous iteration of the snowflake (originally for the Haskell logo competition - they rather nicely repurposed it).

You can piece this together, from the Haskell wiki, the FAQ and a Nix blog entry from 2009, but it's not particularly obvious.
{kind=link}
I do think it's pretty fair to simply credit the new logo to Tim Cuthbertson - it's clearly a significant iteration (and improvement!) on the original, and I wouldn't want to muddy the waters around a key piece of IP of a major project. What does surprise me, though, is just the way that the Internet as a whole degrades non-current information. I'd assumed that if I ever wanted to assert "I originated the Nix lambda-snowflake logo", that this wouldn't be hard to prove, and yet it's really not obvious any more!
Posted 2023-11-17.
Game review: Iconoclasts
Some time ago, I bought Iconoclasts for the Switch off the back of some positive reviews. I never got around to playing it, although my kids did, and seemed to enjoy it. I finally got around to playing it, and I really didn't like it. I completed it, mostly because I wasn't going to let this annoyance get the better of me.
The thing that really stood out to me at the start was the absolutely dire writing. Everything from poor word choice through unclear dialogue through to making the characters 2D cutouts (perhaps appropriate for a 2D platformer? :p). The characters are awful and the plot is very ropey - although it's not entirely clear to me if this derives from the writing, or is independently bad.
The pixel art is also awful. I remember a really good '90s pixel artist saying that the point of their work was to "hide the pixels", and put in more than was really possible with the technology. This game, attempting retro without properly understanding it, takes the opposite approach, of showing off the pixels, not only making them big, but badly used. I don't know if they actually used a limited colour palette, but the feeling is of using many colours, but mostly bad ones. The magenta that runs throughout brings back the worst of '90s platforming, not the best.
These things could be perhaps forgiven if it weren't for the gameplay. This grates at so many different levels. At the level of the simplest mechanics, it's fiddly: You get a spanner with multiple upgrades that can be used to wrench, hit, spin and hang from, three guns with two modes, plus an electrified version of most of the above, and can jump on enemies in two different ways. Then you need to match the specific attack out of all the above combinations against the specific enemy. Or the enemy might just be indestructable.
The movement mechanics are deliberately restricted to create non-sensical puzzles: While your character can do all kinds of jumps and climbing onto ledges, they can't simply clamber onto a platform about a metre high. This weird inability is the backbone of almost all the puzzles in the game.
Moving onto level design, the game has decided that the key element of Metroidvanias to reproduce is "tedium". I kept finding areas to explore that lead to... nothing yet. I was clearly supposed to come back later, tediously recrossing existing areas. It didn't feel so much like the levels unlocking and becoming different with new powers, as just boring back-and-forth make-work.
And then bosses are even worse. They're overly-cluttered, and multi-staged. They're an exercise in trying out the various weapons combinations and trying to learn how to dodge attacks (if they can reasonably be dodged), while trying to keep up caring enough to not just fatalistically die repeatedly or walk away from the game. Done well, these bosses would be challenging and interesting, as it is, they're ugly, messy, tedious, an attack on the senses and intellect.
The bosses are usually preceeded by incredibly slow, and obviously really badly written cut-scenes. Did I mention how annoying the monospace fonts with occasional ALL CAPS, badly scaled letters and shaky letters are? They really take the dialogue down to an even lower level. I started to think that the cut scense were punishment for dying, until far too close to the end I found the undocumented way to skip them (the button that usually brings up the map etc. can be used to skip).
I think the problem with many modern platformers is that they don't know how to deal with death. '90s console platformers gave you limited lives before taking you all the way back to the start. You were expected to learn the game well enough to complete it in a few hours, once you were good at it. In contrast, modern games expect save points and plenty of gameplay from end-to-end. Death should be enough of a roadblock to stop you just hammering each boss and lucking through it.
The trend seems to be to make the bosses harder, particularly by making them less obvious in how to proceed, so you keep throwing deaths at it until you find the weak point. And, quite frankly, this isn't as fun.
I dunno, maybe I just played the wrong games in the '80s and '90s. I just like Sonic. It wasn't particularly hard, but it was enjoyable and rewarding. Mickey Mouse: Castle of Illusion, QuackShot and Aladdin all just looked really good and played really well, and didn't associate platformers with blocky misery in the guise of fun. I tried NES Mega Man on an emulator, and why that's what people want to base their retro games on, I don't know. Is it too mjuch to ask to have something that's fun and looks good?
As I was saying, Iconoclasts doesn't really know how to deal with death. Beyond making boss fights annoying, it's looking for a way to punish you for dying. The mechanism it's found is to have a set of "tweaks", power-ups that break as you take damage, that don't get reset on death. Unfortunately, in order to prevent the game putting you into a downward spiral, the game plays fine without tweaks, so all the effort put in around them seems utterly unnecessary.
Between tweak crafting, and all these power-ups and attempted plot points, it feels a little bit like it's trying to pull in elements of RPGs or something. Certainly you spend much of the game going around as a "party", despite this being indistinguishable from being on your own from a gameplay point of view. The developer clearly wanted to build something grand, but why not just... good?
Sometimes it's really not clear if a puzzle needs to be completed to progress the game, or just get more raw material for tweaks. The puzzles are a mixture of fiddly and logic-y, and furthermore it's sometimes not clear which it is, so you don't know if you're failing because you're taking the wrong approach, or it's just annoying. It's a hard-to-read game. You might claim it rewards experimentation, but there are many games that do so much better, through well-structured subtle hints and feedback loops.
Overall, the design is largely unoriginal in ways that are cliched for retro platformers (cheesy monospace font dialogue, jumping on enemies), with bits of originality that are just plain bad (your character can climb onto a ledge they're hanging off, but can't actually clamber up three feet, purely to set up the game's puzzles). It is just soooo frustrating that after so many decades of 2D platformer design we still get games like this.
It's a sprawling game of considerable complexity. There's clearly been a huge amount of effort put into it. The plot is ambitious, even if the overarching "kill your gods" message is about as unsubtle as is possible. The way that you literally smash statues for tweak energy is quite funny in blatancy. The unlikeable characters (both "good" and "bad") suffer pleasingly, even if there's an unfortunately happy ending. There's sufficient content that I was really getting bored waiting for the end of the game (a sinking feeling with every extra boss).
Yet, and I think I've made this pretty clear, for all the effort that was put into this game, it's not fun. There were '90s EGA platformers that were significantly more fun. I tried Hollow Knight, and I was sufficiently impatient at the time to bounce off it, but I could see what it was trying to achieve, and it did it well. This does not.
Why? It appears to be a single-developer indie project. The thing about one person doing the art, music, game logic, level design, script etc. is that either it's a modern masterpiece, showing off genius, or it's just pretty darn mediocre in most areas, backed by an overinvested dev and people fawning over the idea and ignoring the reality. Not as smug as Fez but some similar vibes.
I appreciate Hollow Knight. I really enjoyed Super Meat Boy, even though I didn't get very far. These are games that have thought carefully about playability, possibly even fun. Iconoclasts, on the other hand, is simply a vast monument to mediocrity.
Posted 2023-11-14.
FIR and IIR filters
Almost every explanation of FIR and IIR filters has not worked for me. I have a reasonable background in maths, but the maths used by mathematicians rather than physicists or engineers. This means I can deal with complex numbers, and more of less Fourier analysis, but anything to do with Laplace makes me go cross-eyed. Somehow, every explanation of FIR and IIR, being framed for physicists or engineers, goes over my head. So, I've tried to reframe it in terms I understand.
This document is my attempt at explanation.
What are these things?
Given a sequence X_n, we can make a FIR filter of it, Y_n, by calculating it as follows:
Y_n = a_0 * X_n + a_1 * X_n-1 + a_2 * X_n-2 + ...
for some finite number of terms.
It's a finite impulse response filter, because if you put a sequence with a finite number of non-zero elements in, you get a finite number of non-zeros out.
An IIR, on the other hand, looks like this:
Y_n = a_0 * X_n + a_1 * X_n-1 + a_2 * X_n-2 + ... + b_1 * Y_n-1 + b_2 * Y_n-2 + ...
Again, with a finite number of terms.
Because of the feedback, a finite impulse in can lead to an infinite response out. They tend to make better filters.
This looks very discrete
Yes. While the underlying systems are usually continuous, when dealt with as digital filters, they're discrete, and to avoid the pain of "How does this discretise?", I'm modelling it as a discrete system.
These filters are linear
We'll deal with IIR filters, treating FIR as a subset of IIR.
Let's say we have the same filter being applied to seqeuences X1 and X2, producing Y1 and Y2:
Y1_n = a_0 * X1_n + a_1 * X1_n-1 + a_2 * X1_n-2 + ... + b_1 * Y1_n-1 + b_2 * Y1_n-2 + ...
Y2_n = a_0 * X2_n + a_1 * X2_n-1 + a_2 * X2_n-2 + ... + b_1 * Y2_n-1 + b_2 * Y2_n-2 + ...
What would happen if, instead, we applied the filter to the element-wise sum of X1 + X2 (call it Z)?
Z_n = a_0 * (X1_n + X2_n) + a_1 * (X1_n-1 + X2_n-1) + a_2 * (X1_n-2 + X2_n-2) + ...
+ b_1 * Z_n-1 + b_2 * Z_n-2 + ...
Z_n = a_0 * X1_n + a_1 * X1_n-1 + a_2 * X1_n-2 + ...
+ a_0 * X2_n + a_1 * X2_n-1 + a_2 * X2_n-2 + ...
+ b_1 * Z_n-1 + b_2 * Z_n-2 + ...
I will now do what feels like some slightly dodgy induction. If we
start calculating our sequences at index 0, we have to find some
values for index i, where i < 0. We'll
assume they're zero. This gives us Z_i = Y1_i + Y2_i
for i < 0. Inductively, if we assume
Z_m = Y1_m + Y2_m for m < n:
Z_n = a_0 * X1_n + a_1 * X1_n-1 + a_2 * X1_n-2 + ...
+ a_0 * X2_n + a_1 * X2_n-1 + a_2 * X2_n-2 + ...
+ b_1 * Z_n-1 + b_2 * Z_n-2 + ...
= a_0 * X1_n + a_1 * X1_n-1 + a_2 * X1_n-2 + ...
+ a_0 * X2_n + a_1 * X2_n-1 + a_2 * X2_n-2 + ...
+ b_1 * (Y1_n-1 + Y2_n-1) + b_2 * (Y1_n-2 + Y2_n-2) + ...
= a_0 * X1_n + a_1 * X1_n-1 + a_2 * X1_n-2 + ...
+ b_1 * Y1_n-1 + b_2 * Y1_n-2 + ...
+ a_0 * X2_n + a_1 * X2_n-1 + a_2 * X2_n-2 + ...
+ b_1 * Y2_n-1 + b_2 * Y2_n-2 + ...
= Y1_n + Y2_n
Hence, by induction, Z_n = Y1_n + Y2_n. It's linear!
This means that, for any input, to get the output of the filter, we can break the input down into convenient signals, pass them through the filter, and sum the results together.
Convienient signals like... sine waves. If we know how the filter reacts to sine waves, we know everything about it. (Thanks, Fourier!)
Filter response to a sine
For our purposes, it's easiest to treat sine/cosine as the real part of a complex exponenential. Sorry, it just is. Complex addition is just a lot easier than dealing with a bunch of trig identities.
I'm now going to start indexing the sequence with t (for time) as
i is going to be the square root of minus one.
Assume the sequence elements X_t are samples at
frequency s of a cosine of
frequency f. Then X_t = Re (e^(i 2 pi t f /
s)). Let's set w = 2 pi f / s for simplicity
(w is my ASCII approximation to omega, angular
velocity).
Then
Y_n = a_0 * Re(e^(iwn)) + a_1 * Re(e^(iw(n-1))) + a_2 * Re(e^(iw(n-2))) + ...
+ b_1 * Y_n-1 + b_2 * Y_n-2 + ...
and quite frankly we can (assuming the as
and bs are real) just drop the "Re" operators and just
take the real component of Y as we need it, to make our
lives easier:
Y_n = a_0 * e^(iwn) + a_1 * e^(iw(n-1)) + a_2 * e^(iw(n-2)) + ...
+ b_1 * Y_n-1 + b_2 * Y_n-2 + ...
Next, we're going to do that dodgy thing where we assume the form
of a solution, and then check it works. Specifically, we'll
assume Y_n = y * e^(iwn), where y is some
complex (not necessarily real) number:
y * e^(iwn) = a_0 * e^(iwn) + a_1 * e^(iw(n-1)) + a_2 * e^(iw(n-2)) + ...
+ b_1 * y * e^(iw(n - 1)) + b_2 * y * e^(iw(n-2)) + ...
Let's divide everything by e^(iwn):
y = a_0 + a1 * e^(-iw) + a2 * (e^(-iw))^2 + ...
+ b_1 * y * e^(-iw) + b_2 * y * (e^(-iw))^2 + ...
Solving for y, we get:
y = (a_0 + a1 * e^(-iw) + a2 * (e^(-iw))^2 + ...)
/ (1 - (b_1 * e^(-iw) + b_2 * (e^(-iw))^2 + ...))
Interpretation
The value of y as w varies is the frequency response of the filter. It
turns out the frequency response is simply a rational polynomial of
e^(-iw).
What you usually care about is the magnitude of y,
which gives the amplification of that frequency, while the argument
of y is the phase shift that the filter gives to that
signal.
The value of w usually lies in the range between 0 (DC
signal) and pi (the Nyquist frequency for that sampling rate). You can
squint and think of e^(-iw) as providing a bit of
distortion on a linear interpolation of w between 1 and
-1 (most distorted at the highest and lowest frequencies).
All the fancy filter designs are really about choosing a polynomial that gives the shape of frequency response (and phase, for those that care) curve that people want.
The "poles" of filter design are the points at which the denominator goes to zero, creating infinite amplification. Physically, that's resonance, and you probably don't want a pole inside the range of inputs you expect, unless you really, really want a pole there (when what you're building is called an "oscillator :).
Zeroes are when the numerator goes to zero, and that frequency is not passed through at all.
Posted 2023-11-06.
Michael Lewis talks about Sam Bankman-Fried
A friend had a spare ticket, so the evening before yesterday I heard Michael Lewis (Liar's Poker, Flash Boys) talk about Sam Bankman-Fried and the FTX crypto exchange disaster. I thought I'd post on Mastodon about it, but the words ran away a little, and now I have a blog post.
I went into it a little suspicious, since the book's had some not-great reviews, mostly focused on technical inaccuracies.
One thing that came across quickly is that Lewis's focus is on characters, and maybe a bit of stories. Deep technical details are way down the list. OTOH, he spent more than a year with SBF, so I expect his character insights to be pretty solid.
While Lewis was a literal investment bank bond salesman in the 1980s, it was surprising quite how out of touch he was with modern, technical Wall Street, particularly given Flash Boys. He talked about the "obscure" HFT companies you probably haven't heard of, and the entire list was either places it was suggested I interview at, or places I have friends at (I've never worked in HFT - feels too zero-sum).
Moving on to the weird aptitudes and behaviours of SBF, and it was quite "You don't hang out much with maths olympiad types, do you?". To be fair, SBF's social behaviour seemed extreme even by those standards. It was like he couldn't see the point of masking-style behaviour, even though most bright aspie types get that working out how to work effectively with others helps you get what you want.
Yet somehow this failure to comprehend effective interaction is made into a huge selling point. All his flaws are treated like, "wow, so unique". I remember the VC page that stayed up far too long after the FTX collapse talking about basically how impressed they were with his crappy attitude to risk management and self-centredness.
As Lewis spent a year with Bankman-Fried, you'd have expected him to have a pretty good read on him, but if he's hugely abnormal socially, does that cause an issue? Amusingly, it looks like Lewis believes he understands SBF because he's seen so much dishonest behaviour from him.
Let me break that apart a bit: What Lewis sees is a person who just does not think about what other people think. So, for example, during his external-facing work at FTX he's learnt that "people like you more if you say yes", so he just spends those meetings agreeing with everyone, even if he doesn't actually agree. In other cases, his partners would basically say "You're not going to run this algo unless we're around, right?", he'd agree, and then run it when they're not around. It's like he doesn't understand the value of being truthful to people, vs. saying whatever's expedient and assuming that everyone else has the memory of a goldfish.
Yet he's doing all this blatantly in front of Lewis, not hiding it. The same attitude of not modelling others' thoughts about his honesty applies to Lewis, so he doesn't have the mental framework to hide what he's doing from Lewis. It's all very On Bullshit - SBF is not so much a stragetic liar as like the toddler who'll tactically say whatever he thinks will get him what he wants, with no regards to the future. He's not trying to bend the truth, he just doesn't care about it.
Another factor that sounds like it would make Lewis's job harder is that SBF doesn't do facial feedback. For example, he wouldn't smile at a joke. Lewis said SBF resented having to perform these basic social behaviours, but when he started dealing with more people he actually started practising expressions in a mirror. This prompted a question from the talk's host about whether SBF felt emotions like other people did, and... is this where we are, still?! "Do autistic spectrum people have emotions?", really?
Anyway, the question of whether Lewis's assessment of SBF is credible is interesting because there are wildly differing opinions of Sam's motivations, and if Michael Lewis has an opinion based on a lot of personal exposure... is it right? Lewis thinks that Bankman-Fried's thing about effective altruism is genuine (while so many others think of it as a front for self-enrichment).
I think this is roughly based off SBF not having the subtlety to consistently lie about such a thing, but also because SBF doesn't really need money. There's been a fair amount of discussion of his weird lifestyle, but it seems to come down to him having an insane amount of money and nothing much to do with it, because he lives in his head and doesn't care much for material goods. Which I guess is consistent with the "doing it for effective altruism" story.
One thing that wasn't covered is how weird EA has become. Starting with "Maybe it makes more sense to earn a shedload of money and give it to help prevent schistosomiasis than volunteer in an animal sanctuary?" and getting to "We must spend millions upon millions defending against a hypothetical AI uprising!" is quite the ride.
I get the impression that Michael Lewis's view of "Did Sam Bankman-Fried commit fraud?" runs along similar lines to how SBF approached honesty: SBF didn't set out to commit fraud, he just didn't see the point in controls, didn't care about the laws, and just did whatever he liked. It's almost not even negligence, because that would imply that SBF understood he should have cared. It's like the concept of "bullshit", but for financial regulation compliance and controls.
There was just so much that Bankman-Fried didn't see the point of, and didn't do. He inherited a dislike of org charts from Jane Street (where a friend of mine is finding the aforementioned lack of clear organisational structure frustrating), leading to a very thorough tyranny of structurelessness at FTX. One of the weirdest things from the talk was finding out that the only actual org chart that exists was compiled secretly by the company therapist, as a way to make sense of the mess.
All this disorganisation and lack of controls leads to the question: Where were the adults in the room? Sam didn't believe in "old people", so they didn't have them. The need for experience is something that needs experience to realise! How did he get away with calling the shots like that? It looks like all the investors had fear of missing out, and FOMO is one of the driving factors behind venture capitalists behaviour, just like with Theranos. Don't ask too many questions. It's other people's money, anyway.
This in turn leads to another question that wasn't asked that evening: Who's responsible? He couldn't become a multi-billionaire in a year without leverage - people gave him money. Again, looks like those VCs that enabled the lack of controls. My suspicion is that the same feeling of "he's a character" that lead to Michael Lewis to start following SBF around for a year before FTX collapsed was also what drove the VCs to fund him. "Throw money at unusual people" is a substitute for "Throw money at competent and effective people", I guess.
One of Lewis's final thoughts seemed particularly poignant to me: Sam Bankman-Fried judged things by outcome rather than by intent. Against that background, for everything he's done, he's damaged the things he cares about and helped the things he dislikes. Ow.
Michael Lewis was entertainingly feisty. There were some good, interesting, and even funny audience questions. It was a fun, and even a little informative, evening.
Posted 2023-10-11.
My first attempt at 3d printing
I do not have a 3d printer. What I did was submit some files to a 3d printing service, and get the results back.
It all started with wanting to tidy up my study. I found an unfinished "Revell Attack Fortress SDF I" Japanese robot model kit from the late '80s or early '90s. Clearly the way to tidy this up is to finish constructing it. Unfortunately, it was missing one piece. What to do? Also clearly I needed to use 3d printing to reconstruct the missing piece and finish the model.
As documented on Mastodon, my first attempts to reconstruct the model were with photogrammetry via Meshroom. This was incredibly cool tech. and very fun to use, but the result was something that looked really good when textured that was a blobby mess geometrically. Plan B was to measure the thing carefully and mock it up in OpenSCAD. This worked a lot better, even if OpenSCAD is inexplicably slow to "render" the constructive solid geometry models.
Around the same time, I was trying to put my old Z80-based CP/M-running SBC in a case. I'm pretty consistently rubbish with these projects, the end result looking hideously bodged, but I thought... maybe I can do better with the front panel this time? If I can 3d print the mounts for the various connectors etc., it might look ok for once. So, that's what I set about doing, again in OpenSCAD.
All this came in just under teh minimum order size for the company I was looking at using, so I rounded out the order with a model of the Cobra Mk III (from Elite) as a keyring fob, mostly as an excuse to exercise a different material.
I used SGD 3D, with SLA for the model parts and keychain ("Rigid Resin 4000" and "Flexible Resin" respectively), and SLS ("Nylon PA12 GF") for the front-panel components. I was really interested to try something other than the FDM printing with PLA we have at work, that I wouldn't trust for this level of detail.
Three weeks later, they shipped me my printed parts.

The SLA parts have support structures, so it was time to get clipping. I started with the flexible resin key fob. Yep, it's pretty flexible, and transparent. For the right applications it'd be pretty cool.

On the upper side there's a lot of detail visible - the resin printer approach works really well for that. On the other side, the detail is rather marred by those supports.

Moving on to the model pieces, I got further practice at clipping supports. This material is pretty brittle. Fine for detailed models, but not so good for mechanical things. The technology is capable of really fine detail, so it's a bit frustrating that they printed it the other way up to my request and at an angle, so that the surface that should have been flat was covered with bumps from the support points and banded from the lack of plane alignment. A couple of the holes, that I believe were close to but not below minimum size needed a bit of manual poking.
I bodged on a couple of coats of paint (to do this correctly you should be using more layers of thinned paint, but I'm very lazy), which actually seemed to emphasise the flaws in the printing, but the difference is minimal at any distance, even if you can spot it close-up.

Have a picture of the finished model. Yes, a 12-year-old could do better. I don't have the patience or skills of a good 12-year-old. :p Still, It's Done.

The SLS'd nylon, on the other hand, was pretty much exactly what I wanted. No supports, no obvious artefacts (although I think one of the faces was just on the edge of warping), and a firm yet flexible material that is useful for more than just pure aesthetics. The OpenSCAD designs fitted the breakout boards nicely. I think it's a process I'd want to use again, although I'm not sure whether to go with MJF (multi-jet fusion) or SLS again next time.

Posted 2023-10-08.
Raft, done weirdly
From time to time I'll think about consensus protocols, and then slowly relearn how Raft works. I've never found the Raft paper to be particularly helpful - it focuses on how Raft should work, rather than how it doesn't fail to work. This is not entirely fair, in that it does describe the properties that remain true, and then show how they remain invariant through the various operations.
What I end up doing is reconstructing a mental model in my head that's invariant-first, and going from there. What I should do, and what I'm finally doing this time, is writing this model down so that I can shortcut to the important bit when I forget. Maybe it'll be helpful to someone else?
The goal in my version of Raft is to build a transaction log. You ask the system to append an item to the log, and if you get a "done" back you can be sure the transaction you've just submitted will be in the log, in that position, from here on out.
In my version of Raft you're given an unreliable computer that can reset at any time (losing all its state), a ticket machine and a semi-reliable storage mechanism. I hope "a computer that can reset at any time, losing all state" is understandable and relatable. The ticket machine is also pretty straightforward: Every time you call it, you get the next number. It returns numbers in an increasing order, and never returns the same number twice. The memory is just a little bit more complicated.
The memory system runs something like this: It stores a set, and has a read and a write operation. If you write and it returns before your unreliable computer explodes, you have a complete write, and it's durable - any time you read, you can get the value back. If it explodes, you'll have an incomplete write - when you read, you'll get the value back non-deterministically. To simplify, when you read and get a value back, you can't be sure if it's part of a complete write or not, but you can (try to) make it complete by writing the value again (in real Raft you can sometimes know a write is complete when reading).
This isn't an exact match for what Raft does, but it's close enough to be continuously deformable into the published algorithm.
How do we build a transaction log with these tools?
First, everything written needs a unique id to identify it. When our unreliable computer starts up it grabs a ticket, which we'll call the "term number", and then keeps its own counter. Each entry is identified by a unique (term number, counter) pair, which monotonically increases with time (I guess you could grab a new ticket every time, but this'll be cheaper).
Then, we need to sequence the transactions. We can't assume that every single write will be in the transaction log - we may start a write, and then crash, leaving an incomplete write from which we can't recover the data. So, each transaction will refer to the previous transaction's (term number, counter) pair, creating a chain of transactions.
Without further constraints, this chain could actually be a tree. The main trick of Raft is working out how to create a unique main chain on which all committed transactions live.
In practice, we do generate a tree, but we ensure there's a main backbone of committed transactions. Off this may hang uncommitted attempts to build a transaction, but the core chain holds all committed transactions.
We're going to make the rule that every non-leaf entry of the tree is a complete write. After all, we don't want entries whose predecessors aren't available! So, before writing a new entry refering to an older entry, we must know that older entry is a complete write - either because the write is in the same term and we saw it complete, or it's from a previous term but we have rewritten the entry and seen the rewrite succeed as complete.
One of the side-effects of this is that if we see an entry with another entry chained after it, we know that the earlier entry is definitely a complete write.
As things can get messy around having multiple incomplete writes outstanding (if our unreliable computer keeps crashing near the start of a bunch of terms), and then deciding which ones to complete, we can't actually just guarantee that every complete write is part of the committed backbone transaction log, but we can guarantee a different invariant: Any write completed in its own term (the term number being written is the current term) is committed (will always be on the backbone).
To keep this invariant, all a new term needs to do is to always build on the highest (term number, counter) entry it sees (having rewritten that entry to ensure it's complete). Why does this work? Let's say the new term immediately follows the last term with a committed transaction. We'll be building on either that transaction, or the incomplete entry chained immediately afterwards. In either case, the chain includes the last committed transaction. If there have been other terms in-between with transactions not committed during their term, they will have been chained onto the last actually committed transaction (by induction), so we can safely build on those too.
And that's morally the equivalent of how Raft works. The unreliable data store is just "keep writing until you've written to a majority of the nodes" to write and "union the results of everything you can see, assuming you're reading from a majority of the nodes" to read. The unreliable computer is "do a leadership election, have the elected device run the algorithm", and the ticket machine is a side effect of the the described election algorithm". Raft does a bunch of stuff like delete the entries that aren't on the backbone, but the end result is the same.
That's Raft, done weirdly. I think I'll take a look at Paxos again.
Posted 2023-07-15.
AI, the Industrial Revolution and Returns to Labour and Capital
Given how similar the potential effects of AI are to the changes brought about by the Industrial Revolution I'm surprised more people aren't taking the chance to really think about it. The economic effects of most technological improvements follow a similar pattern, but the Industrial Revolution was a particularly big shift, as AI may be, making it a particularly attractive target.
Technologically, the story runs something like this: A lot of slow, somewhat skilled work got replaced by machines working quickly and some less skilled labour. Economically, productivity went way up, and overall people got more stuff cheaper, and it was all to the good. Before, most of the money went to the labourers. Afterwards, well, machines are expensive and unskilled labour is cheap, so the money mostly went to the owners of the machines. There was a shift where the returns to labour decreased and returns to capital increased. This may have caused some social problems for a while, but, y'know, all's well in the end, right?
The unspoken assumption about AI is that things should pan out in the same way. There's talk of "there will be winners and losers, but overall AI will benefit humankind", but no-one's so gauche as to be explicit that we're just assuming the winners will be big tech and the losers will be anyone creative. If we say that, someone might questions why that has to be the case, rather than just assume that things will play out like the industrial revolution.
There are a bunch of reasons why it shouldn't play out like that, and why we should choose to not let it play out like that. At the very start, the industrial revolution was not planned. We did not have the benefit of the hindsight of having done it before. We know what history looks like, and can choose to do something different. Choosing to not intervene is also not the natural order, it is definitely a choice.
So, why is this different from the industrial revolution? The before state is returns going to labour: People who write text and draw pictures get paid for their work. The assumed outcome is that in the future we'll be giving a smaller amount of money to big tech, and no money to creators. However, this is not economically driven, this is driven by regulatory structure and an assumption that history should repeat.
Returns to capital are usually driven by the fact that deploying capital is expensive. Machines are expensive. Companies that can spare the money to invest or have an intellectual property advantage use that to get returns on their capital. Except... AI is a mess commercially right now because no-one has a moat. No-one has built a huge advantage from their model. There are good open source models. Even training infrastructure isn't the huge advantage people had hoped, as people have found ways to make smaller models that are almost as effective, and adapt expensively-trained models cheaply. People wanted the value of AI to be in the technology and infrastructure, to enable returns to capital. It turns out that's not where the value is.
The value is in the training data: The creative output of real humans. The bit that's currently being valued at nothing in an AI world. The value of human labour is usually determined by supply and demand. In the industrial revolution, returns to labour went down because a smaller amount of less skilled work was required to produce the given output. In the AI scenario the price of the input data is zero not because that's the market price of producing that data, but because we've currently got a regulatory framework that just allows people to take it.
The business model of AI right now is largely attribution laundering. If I search for something on the web, I used to get a link to content made by people, they get their attribution, they find some way to monetise the provision of that information. The move has been to have search engines try to answer questions directly, grudgingly providing a link back to the original source and hoping you won't click through. The AI model is to put all the data into a big pot, stir it around, serve up an answer, and give zero credit to the people who contributed to the answer. The answer still comes from the source data, but all attribution, all sense of owing anything, has been wiped away.
This is both ethically and economically broken. Anyone who loves creating and sharing art, is surely not in favour of building a system that destroys the ability of people to make money from that art and otherwise disinventivises its production. Taking such art freely given and making it into a weapon against the gift-giver cannot have an ethical basis.
In some cases it might be argued that the T&Cs of services enabled this use in training data. This seems about as sound as trading Manhattan island for a pile of beads, but is clearly not the limit big tech desires. In this article Sam Altman claims that "material on the public web would be fair game". Interestingly the true value of this data is clear to him when he says "companies should have the right to say they do not want their data used for AI training" - the goal is to structure winners and losers on a regulatory basis, rather than by optimising ethical and economical goals.
This brings me on to the economic side of things. We build economic structures that incentivise the behaviour we want. For example, free markets might look like a self-organising structure, but they're built on property rights. Historically, we have wanted to encourage human creativity, and we ended up with copyright law. The current AI regime tries to end-run copyright. The only reason to give up on protections in the face of a much bigger threat to IP is if we no longer want to encourage human creativity.
AI depends on its training data. If we stop contributing human creativity, and populate the world with AI generated art and text, asymptotically we'll have AI-generated media based on AI-generated media. What that will look like is not clear, but it looks like a recipe for destroying originality, a key driver of change and growth.
Who knows, maybe I'm wrong, maybe human-based creativity is overrated, and not that valuable. From an economic standpoint, there should be a price, and it should be discoverable, and anyone wanting to work for that little value can feel free to. Forcing the value of human creativity to zero makes no sense either for the free market invisible-hand-ers, nor for the "build an economic system to enable the outcomes you want" crew. The only people it works for is those who want to take others' work for free, label it as their own, and sell it.
To summarise:
- Assuming that the "winners and losers" story of the industrial revolution should or must be followed by an AI revolution is lazy and naive.
- Increasing returns to capital are not justified by the technology.
- Decreasing returns to labour are not justified economically or ethically.
- Existing intellectual property laws need to be extended to prevent attribution-laundering by ML models, and give copyright holders strong protections over how their creations are used.
Posted 2023-05-25.
What's the point of trivia questions in interviews?
People are being dumb on the internet again. Specifically, people claiming that cheating on knowledge questions in interviews is fine, because they're meaningless anyway in a world of Google.
I'm going to start with a detour on the cheating angle, because as an almost-excessively honest person, this really, really gets me. There was some kind of hand-waving around how tech interviews are bad and broken, and hence cheating is justified. The only possible way I can see for someone to justify this is if the interview process is so unfair such that hiring someone else over you would be a huge injustice, and there are no other reasonable alternative jobs (working in places that have better interview processes, for example) so you're forced into the situation and that's... a long shot.
I think the cheater's view is that they're just making their relationship with the company fairer. The company unfairly bars them with a bad interview, and they're just fixing that. Thing is, they're not cheating the company, they're cheating honest candidates. Do these people really think they're better than someone else who can perform just as well in the interview, but has the answers in their head and doesn't need to search? They probably do. They're probably wrong.
Any normalisation of cheating is toxic to society. Loss of trust creates horrific feedback loops engendering further loss of trust. Framing cheating as a harmless mechanism to address ill-specified personal injustice caused by a huge enemy is wonderful framing, when it's just selfishly making life worse for honest people.
Anyway, with that rant out the way, what's the point of trivia questions in interview?
To be clear, I'm not a great fan of trivia questions. I prefer to deal with questions designed to understand how people think, and assume that someone with the right way of approaching problems will be able to learn effectively. This bias comes from the fact that the roles I deal with require clear thinking and a lot of specialist knowledge learnt on the job, so pre-existing knowledge is a bit less valuable in many situations. However, "trivia" questions aren't useless.
What's the value of knowing things that are easily findable on Google?
- Demonstration of learning In most roles, there are things that you're expected to know. They're useful, practical, it's expected that you'll have come across them, and that having come across them they'll be in your head. Sure, it's easy to find in Google, but you still should know it, and if you've managed to avoid learning I'd like to know why.
- Fluency If something is in my head, I don't need to look it up. Looking something up is quick and easy nowadays, but not as quick and easy as just knowing it. I've spent the last few days working through a new code base in a language that's new to me. I can poke around and not be blocked because a Google search tells me whatever I need to know, but I am still making progress an order of magnitude slower than on systems I am fluent with. Fluency really matters. For all the talk of generic 10x developers, I think this is just fluency explained badly. So, yes, fluency counts.
- Unknown unknowns To be able to use a piece of knowledge, you need to be aware of its existence! It's enough to know about something to look up the details, but you still need to be aware of it. Being able to look things up is no help if you don't know there's something to look up, and being anaware of the right way to do things is an excellent way to do it wrong.
It turns out that a full-force 180-degree disagreement with a bad idea is often also a bad idea. Trivia questions don't reveal deep insight, but testing knowledge is not completely invalid. And I say this as someone who's pretty poor at memorising things (part of why I love building systems that make sense, rather than relying on memorisation of a thousand things that don't really make sense).
The attitude that being knowledgable is massively overrated and you can just muddle through with a search engine is curiously self-serving. You can be awesome at everything without putting effort in, and failure to recognise this is injustice in the world against you. It's a life of living on the Dunning-Kruger curve. Of not quite being sick of experts, but being confident you are an expert. You read a web page.
This is not to say that expert-level people don't fail to memorise stuff that's not that important and easy to look up. That's certainly my excuse. :p Maybe there are interviews that really do manage to focus on details that experts don't care about, but at that point it's a bit of a straw man. Would you actually want to work there?
The alternative is to believe in expertise, and believe in specialisation. I am a strong fan of breadth, but there should be depth, and you're not going to be deep at everthing. That's ok. Embrace it, grab more specialisations over time, maybe you have an interview where you don't know something because it's not your thing. That's fine.
It's been 8 years since I've been in finance. My recall of the exact Black-Scholes equation is not there, but I can still do the intuition. I'm ok with not getting a finance job because I can't remember it, but I'd be incensed if someone got such a job over me by reading the equation off a web site! Knowledge is funny.
Anyway, enough rambling. Sometimes you just want to vent in a way that doesn't fit in a microblogging post.
Posted 2023-05-10.
On Domain-Specific Languages
I wrote a little bit about CMake the other day, which left me thinking "I've done a fair amount of work on domain-specific languages, what do I know about how to get them right?" aka "It's easy to criticise"!
I've written a bit about DSLs before, mostly from the point of view of configuration languages. I'm now going to try to approach it from another angle: How to make a good DSL.
Structure the DSL to match the domain
In my exotic derivatives payout language FPF, I included a "fold" functor. In retrospect, this was sub-optimal. We nearly always wanted to perform some aggregation across a set of assets or a set of dates. These have different semantics: The former is usually a basket of stocks evaluated together, while the latter represents doing something in timesteps. By distinguishing between the two, you can more cleanly manage various aspects of the trade lifecycle - a time fold represents lifecycle steps whereas an asset fold doesn't.
In a similar way, we started supporting "strategy trades" with FPF. You don't need the details, but they were a poor fit for the existing infrastructure, and the experience sucked. The language should match the domain.
Outside DSLs, a similar thing you see is the effort C compilers need to go through, reversing "for" loops into the underlying iteration structure. Is this a map, parallelisable over an array? The programmer knows, the compiler wants to know, the language obscures. How sad.
Mathing the domain often means making the DSL declarative rather than imperative; expressing intent rather than a detailed plan. The canonical example is a build system (like make) - express dependencies and how to build each step, and let the system do the rest.
You see the same idea with SQL, and in the infrastructure world this is "intent-driven configuration", where the DSL system will do what's necessary to close the gap between the config and reality.
A key thing to realise is that declarative is not always better. Sometimes the domain requires control. Vanilla SQL leaves so much unspecified that performance is unpredictable - horrific for the production serving path. A naive intent-based configuration system skims over important aspects of how to roll out incrementally and safely.
Consider carefully how to map the domain to your language.
Consider your users when designing the DSL
In my limited experience, DSLs have two core demographics: A small number of experts, or a large number of passers-by.
In the former case, you're building a tool that will be heavily used by a small number of people. It's probably a key part of their job, and the investment in the DSL is to make them more efficient. I dealt with this in banking a couple of times, with FPF and with a language for algorithmic trading. It's really nice: You can do subtle, clever things, and your expert users will thank you for improving their effectiveness.
In the latter case, you're dealing with one corner, often neglected, of a wider world, often incidental to the key role of many, many people. CMake is an example of this. Parser generators and other mini-languages fall in this categoy. Users don't want to become experts, they want to get the job done. Anything subtle or complex will make your users hate you. The tool should be obvious, guessable, and friendly to untrained users. This is really hard. I am glad I've never needed to do this
Languages need decent tooling
Like pets, DSLs need a lot of tedious extra work to thrive. In particular, they need debugability. Ranging from sensible syntax errors through the ability to trace execution, maintainability is probably the biggest tax on DSLs. Please don't neglect this angle, particularly if you're writing a "many shallow users" DSL.
Is this a configuration language?
Pretty much anything can be shoe-horned into a configuration language, because code can be expressed as data. However, some things have a natural representation, and fighting that leads to sadness. XSLT still upsets me, an XML transformation about as ugly as it's possible to be, just because it felt it needed to be represented by XML.
If you really are just trying to express something fairly config-ish, such that formatting it as a config file does not obfuscate the meaning, then use an existing config library/language. There's no point reinventing the wheel in a well-populated space, especially if it increases the barrier to entry on a "many shallow users" DSL. "Few expert users" situations tend to be much less like configs.
This is probably where I can get a personal grudge out: In a workplace of almost universal protobufs, it's very tempting to configure everything as one, and... it can get ugly. Do you really want to express "5 < 10" as "left: 5, op: LESS_THAN, right: 10"?
Have you considered an Embedded Domain Specific Language?
A cheap way to make a DSL is to embed it in another language. This can decrease the debugability/maintainability, but you understand trade-offs, right?
"Embedding" here usually means providing functions that generate their own syntax tree, that can then be interpreted. Sometimes you build a mini-language by having the functions directly do the thing they describe, but you get a lot more flexibility by generating the syntax tree. I'm not an ML person, but I think this is the approach behind TensorFlow, for example.
I really like EDSLs, and they provide a spectrum from full access to a general-purpose programming language through to a highly-constrained language.
There are some subtle constraints on EDSLs. As evaluation generates a syntax tree (well, DAG) from the call tree, let-binding and other structural hints from the original syntax are lost. This works against debuggability and makes analysis harder.
Think carefully about the edges of your language
If you are writing an EDSL, you need to choose your embedding language carefully, and consider how much of the original language you support. Haskell is a surprisingly nice language for embedding in, and it's easy to disable the standard prelude. Lua also makes it straightforward to control exactly what functionality is available - e.g. creating a sandbox with zero filesystem access. Python is a perennial favourite for embedding DSLs, but my experience has been that it's a right pain to sandbox.
You need to decide whether you want you DSL to basically be the embedding language with a few extra features, or your own language that just happens to share a syntax. This also ties up with whether your DSL should be Turing-complete, as I discussed previously. Spoiler alert: I favour constrained languages as more maintainable.
Python inevitably encourages you to write Python programs with your own extras on top. I've seen multiple projects at scale where there was a big clean-up effort later to make the DSL code-base into a properly constrained language, taking out all the general-Python-isms. It's miserable. I personally think the lesson is to not use Python for EDSLs, it's too leaky, but no-one listens to me. ;)
Use programming language theory
Either you decide up-front that you prefer a proper stand-alone language, or maybe you've outgrown an EDSL. If you're heading down that path build a proper language. The theory is there, use it. Design a syntax that looks like a proper programming language, with an intent to be used, not some can't-be-bothered mess.
Here, I'm clearly looking at CMake and its ridiculous confused-config-language syntax ("else()"? Really?), but also at TeX and its horrible backslashed macro messes obscuring a Turing-complete language and making proper work on (La)TeX styles incredibly tedious.
At a smaller level, it also means taking syntax seriously so that you don't end up with "but it seemed like a convenient shortcut"isms like the way make cares so deeply about tabs at the start of lines.
Obviously the language you're building shouldn't look like a config language, because if it did, you'd be using an existing config language.
Don't build a text-manipuation language
Unless your domain really is text, don't make your language a text-processing language. By this, I mean you shouldn't look to languages like the Bourne shell or Tcl for inspiration. Don't build a templating language based on textual substitution.
Such languages are incredibly brittle. If your DSL has any security requirements, it'll screw them up, since plain textual substitution inevitably leads to escaping issues. You can get yourself in a pickle trying to work out how many levels of evaluation are needed to substitute all the variables in all the strings that contain other variables. And just fundamentally, you're not modeling the domain any more, are you? You're playing with strings.
Any time I see a DSL with $DOLLAR_PREFIXED_SHOUTY_VARIABLES, I get really twitchy. I've not been comfortable writing code like that since BASIC with line numbers. Shell is not a well-designed programming language, and anything that decides to ape it is ill-thought-through. Shell is compact and convenient, admittedly, but it is quite possible to build convenient, efficient DSLs without copying a syntactic approach associated with unmaintainable hacked-up code. We have learnt a lot in the last forty years.
There's probably a bunch of other hugely important factors to take into account writing a DSL that I've forgotten. There's plenty of space to get a little less abstract and start giving examples of DSLs that are good, maybe develop one myself. However, I feel this is enough for now.
Posted 2023-04-30.