Simon Frankau's blog
Ugh. I've always hated the word 'blog'. In any case, this is a chronologically ordered selection of my ramblings.
Electronics for newbies: Voltage regulation
Once I realised my Nokia 'PSU' was outputting a decent number of unregulated volts, I thought it'd be good to get some voltage regulation in the picture. Given I'm living in a world of slightly retro CMOS (Z80s, etc.), I got a few 5V regulators. I bought myself a few Microchip MCP1826S-series linear regulators, and for fun a couple of switchers - National Semi LM2574N-5.0's.
The linear regulators are really straightforward to deal with and, in conjuntion with a decent-sized cap to smooth the supply from the wall wart, worked nicely. I thought that I'd be fine without heatsinks - after all, how much power will they be putting out? - and indeed it has been fine so far, but it does rather seem an omission now. These little regulators get awfully hot, even when supplying small circuits.
When I do the numbers, this does make sense. Powering a decent number of LED segments can put you in the region of a hundred milliamps. If the regulator's starting with a supply around 10V, the regulator's putting out a decent fraction of a watt. This may not seem like a huge power output, but the thermal resistance of one of these regulators without a heatsink is pretty high. The result is a regulator which is, ahem, 'noticably warm' to the touch. Fortunately, I doubt it's anywhere near a failure temperature. Nonetheless, there'll be a few 'sinks in my next parts order.
The switching regulators are much more fascinating devices. Vastly more efficient, they don't need a heatsink, and as you can get them in 8-pin DIPs, the combination of size and efficiency makes them sound perfect for running off a battery. Or so I thought. Enter Exhibit A.

Er, yeah, that's the kind of size of component I want in a portable, battery-powered device. *sigh*. I think I over-specced it slightly, at 470mH, and perhaps I should have checked the dimensions before ordering, but that's not what I had in mind. I've seen inductors before on PCBs, but... nothing like that.
I notice that my EPROM programmer has an MC34063A to step 5V up to VPP, with a super-tiny (comparatively) 100uH inductor on it. The LM2574 datasheet is really quite dummy-safe, and is very explicit about which inductors to buy for it. I'm wondering if there's basically a trade off between idiot-proofing and designs using cheap, small components, and I've landed in the 'idiot' end. Ho hum. In any case, I've yet to actually build a circuit using the switchers, put off as I am by these huge coils....
Posted 2010-04-03.
To the dark side
I now have an entry on Facebook. Years of resistance have come to naught, and I'm shoving my communications through a commercialised, centralised doodah for the sake of convenience. Go me. On the other hand, it's very convenient.
Posted 2010-03-28.
Electronics for Newbies 3: Faffing with memories
Skipping the fun of voltage regulation, which I'll come back to, I've been mostly playing with SRAM and EEPROM. I'll need these for my plan of building a simple microcomputer. First up was the SRAM. I built a simple circuit to allow me to load values into the SRAM and then read them back:

The structure's probably not terribly clear, so I've since done a schematic:
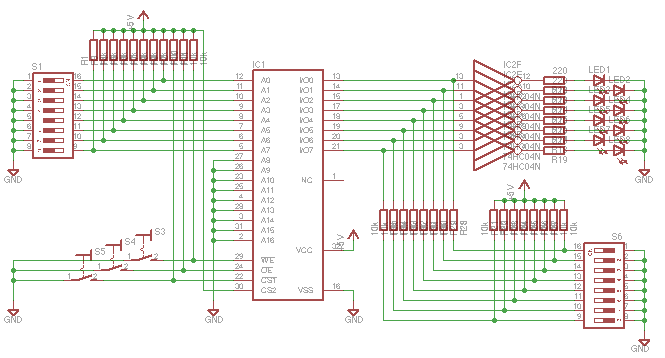
The schematic's messy because I'm too lazy to make it look really pretty. I've skipped decoupling caps and the power supply.
One thing I discovered that while building circuits directly is the easy way to go for simple designs, it doesn't stop you making simple mistakes. For example, when setting up a switch as a CMOS input, connect the switch and resistor in series, and then wire the input line from between the two components. Otherwise it doesn't work so well. Duh. Not so easy to spot in a rat's-nest of wires.
The resistors between the switches and the inverting buffers/SRAM side prevents me shorting an SRAM output to ground through a switch while reading its contents, and it seemed to be a source of surprising weird behaviour. Without enabling the SRAM, toggling some of the switches back and forth a bit left the LED glowing, as if the whole thing had got into some kind of metastable state or something.
Take the SRAM away (even thought it's supposed to be Hi-Z), and the problem goes away. Disconnecting a line from the SRAM and measuring its voltage (with a voltage divider attached, to make sure I'm not seeing some Hi-Z rubbish) showed the SRAM driving the line slightly (even though the thing's supposed to be in high impedance), once I've annoyed it enough on the other lines.
Reducing the size of the connecting resistors from 10k to 220 ohms (they are supposed to be simple current-limiters, after all) reduced the problem, but didn't make it go away. Sticking a small cap (0.1uF, IIRC) on one of the data lines made the problem go away completely! Then I could happily write patterns into various addresses and read them back. Woo.
I still have no idea why it was doing this. Given this was supposed to be a really straightforward circuit, and I'm hoping to build something much more complex involving this chip, running at actually reasonably fast speeds, I'm more than a little unnerved. I'm hoping a shedload of bypass caps will do the trick.
Then my EEPROM programmer arrived, from China, no docs at all. Still, it didn't look too dodgy, so I plugged it into my computer, downloaded some approximately-right looking software from the net, and it worked first time. I wired my newly-programmed EEPROM into the world's simplest reader circuit:

It worked. I had a massively-overkill hex digit to seven segment display converter. I am now officially back to first year undergraduate digital electronics level. Woo-hoo!
Posted 2010-03-28.
E-book Reader Review: The Sony PRS-300
I've been watching the whole eInk thing for a while and finally gave in at the start of the year, going for the entry-level Sony PRS-300. It doesn't have any form of wireless, or any snazzy note-taking features, 'cos all I really want to do is pre-load it with books and read them.
Specifically, I don't want to load it with papers or highly-mathematical books. Novels and maybe some light compsci, yes. The reason for this was the eInk technology - page refreshes are slow (a noticable fraction of a second), and eInk (and indeed most electronic book readers) is really bad for flicking around and browsing, which comes up a lot with the heavier reading where you can't just start at the beginning and read through.
My experience so far has justified this, which is kind of ironic as it's actually a lot better for light novel reading than for the kind of technical text a gadget early-adopter might read. As a novel-reader, this kind of technology is excellent, as it's smaller and lighter than a chunky paperback, let alone a hardback, and it can store a decent number of books. On a commute, you needn't be stuck if you've finished one book and want another.
So, on to the specifics of this device. It's a standard Sony product. So, the hardware feels pretty nice. The firmware is mediocre, and the PC-installed software is dire. Starting with the PC software, it's taken a leaf out of iTunes's book, but copied it very badly. iTunes on Windows imports an Apple look-and-feel... the Sony software on a Mac has a nasty, inferior widget set that e.g. gives really ugly context menus. The software is laggy when it's not downright locking up, and it seems to manage to screw up syncs as often as it can, and have random arbitrary limitations. Yay.
On to the firmware. I've not been using 'proper' ebook formats, since I have little interest in buying DRM rubbish. The formats which look most convenient to me were therefore PDF, RTF and plain text. Most PDF documents render too small to be readable on the 800x600 display in normal portrait mode, but the firmware does fortunately have a landscape mode, viewing a single page in two chunks. If your document has a big margin, it'll happily display this, but fortunately Apple's Preview application allows easy cropping of PDFs, so that it'll take up the entire reader screen. Why is this not built in?
PDF display is not all fun-and-games, though. It can be really very laggy to switch pages. Why not pre-render and cache the adjoining pages, to remove the render lag? Moreover, it's sometimes rather difficult to tell when an operation has started. The eInk is no good at quick updates, but why not have an LED for 'I'm thinking'? There's a charging LED built in already - why not use that? Some buttons require you to hold them down for alternate operations. So, a tap for next page, a press for skip 10 pages. Of course, there's no feedback for when you've reached the 'press' period of time, and it will only start grinding away once you've let the button go, so you've got to guess the minimum hold time that'll get you forward 10 pages as quickly as possible. Argh! So simple features implemented so badly!
Having said that, PDF's been pretty reliable for the docs I've got in that format, although if I had a document in a different format I wouldn't convert it to PDF. I've seen one or two rendering bugs (cheers, Sony), but they've not been killers. So, what's a good format if you have the choice? The software doesn't allow you to specify an author name on a plain text document, and when I briefly looked at it it had some particularly braindead handling of paragraphs, so I quickly dumped it. The RTF support is certainly good enough for novels - 'A Deepness in the Sky' (one of my favourite-est novels, evar) worked very nicely for the 1000+ pages it had. However, I tried converting an RTF with lots of pictures in, and it gave up rendering the text part (but kept the pictures!) after a hundred pages or so. Useless. Oh, and HTML support? I switched to RTF because the HTML support was pretty dire.
Finally, the hardware. It feels very pleasant. The eInk really is very pleasant to read - I've been reading various documents off it for a couple of months now in every morning and evening commute, and it's much more pleasant than the alternatives. The build quality is good. It claims 'up to 7500 page turns', and I can support this claim. Specifically, there's absolutely no chance of it exceeding 7500 turns on one battery charge. I'd be surprised at 2k, and given one paperback can come in at over 1000, I'd strongly recommend taking a charger if you want to take this thing on a holiday. It's surprisingly irritating to be unable to read a book you're carrying because its battery is flat!
All-in-all, it's definitely immature technology. It's too expensive, slow, the particular implementation has Sony's renowned software, and the ebook market is still screwed-up. However, it makes a great novel-reader, and it really does look like the thin end of a very long wedge which will eventually make my lovely bookshelves look as useful as a vinyl collection. I'd give it 15 years.
Posted 2010-03-23.
Electronics for Newbies: Random catch-up
I've been playing about with a few more electronics bits and pieces, but haven't had the chance to write them up (yay, babies!), so to keep up the momentum I thought I'd put up a few notes:
- As I ultimately want to make a simple 8-bit computer, I need to program EEPROMs. I thought about making my own programmer, but I discovered that the ZIF sockets at Farnell at 10 quid, and a full 'Willem' programmer, off Ebay, with cables and delivery from China can be yours for 21 quid. Gah. No contest, really. The downside is that I don't learn from building and debugging my own, the upside is that I get straight to my goal and get a much more mature design. Ho hum.
- Then... I checked Ebay for ZIF sockets, and you can get similar sockets for a couple of quid. So, I could have built it from scratch quite cheaply. Ho hum. Apparently the rule is that if you're looking for this kind of component, do check Ebay first!
- Add simple safety features! Unlike programs, an error can't always be fixed and the program re-run, as one of the components may now be smoke. For what I've been doing, these features come to power-on LEDs and resistors between most things. Resistors in series with pots stop the resistance going to zero are useful, and any time I'm uncertain as to whether a certain configuration could lead to the same point being driven to different levels, I bung a resistor in.
- Learn to use your multimeter. Ok, that sounds obvious. Learn to use your multimeter effectively. I've got a fairly fancy meter, and i's been increasingly useful as I learn its features. On the other hand, I've found the best way to learn to use it is in practical situations, rather than by just reading the manual.
I've played a bit with voltage regulators, SRAM and EEPROM since writing last, so hopefully I'll manage to write those up soon...
Posted 2010-03-21.
Electronics for Newbies: The LCM555
Having not played with any electronics for something over a decade, I thought it'd be time to whip out the breadboard again. So, I thought I'd start with the bog-standard newbie construction, a 555-based blinking LED. This time round, for fun, I thought I'd use an LCM555 CMOS-based 555, since it apparently wouldn't do bad things to the power rail, which is nice, as my eventual goal was to use the 555 as a clock for some sequential circuitry while testing. I looked at the reference circuit design, plugged it into a surplus Nokia phone charger (the LCM555's got a nice, wide supply range, so I didn't think too hard here), plugged it all together, and... nothing.
So, yay, electronics debugging time! For the first time in my life, I actually bothered to learn how the 555 works, rather than treat it as a magic incantation for making something blink. It's actually rather straightforward and neat, but I'd never bothered getting the datasheet before. Once I understood how it worked, I realised I'd been choosing resistor values that were basically shorting it. You'd have hoped something might mention not to do this, but noone seems to bother. D'oh.
I fix that up and... nothing. Even a fresh chip doesn't work. I'm now a little frustrated, but at least I understand how it's supposed to work. I now set up a simple test circuit which removes all that faff with capacitors, so that it should basically run in a steady state and show its hysteresis:
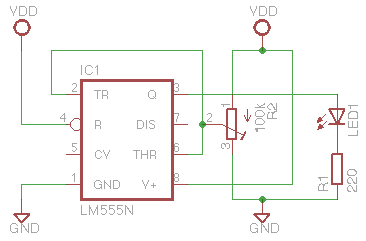
I plug this in, and it behaves weirdly. The the lower level switches on, but then it immediately switches off above this level - there's no hysteresis up to the higher level. Why this asymmetry between the levels? Could it be something to do with the adjustment pin ('CV')? Nope. The circuit should be quite static, without a capacitor, so I shouldn't be seeing any glitchy behaviour. However, when I put more bypass caps in, it goes from on/off to on/slight glow. Hmmm.
Argh. Sticking a multimeter in min/max mode voltage on the power supply reveals a rather high max, and a min of zero. Frequency? 100Hz. Yay, we have a fully-rectified but unsmoothed, yet alone regulated power supply. I'd really assumed that thing would be regulated. Apparently not!
The attachment of a 9V battery (they're convenient in that you can attach them using crocodile clips, if you don't have a proper snap), and everything works fine!
So, now I've been learning up on power supply theory. Horowitz and Hill has been sitting on my shelf for years - I tried reading it front-to-back before, and wedged somewhere near the start of Chapter 3, but I've now zipped through the whole of the power supplies chapter. I only needed about 3 pages, but it's fascinating, and each chapter seems to be about as self-contained as it can be, so it's been surprisingly engrossing.
I could just power my future projects off batteries. Not a 9V, since many of the digital chips I'm looking at max out not far over 5V, but maybe a set of rechargeable AAs. However, I now want to play with all the options, so I've ordered a few battery holders, plus the chips, caps etc. for both linear and switching regulators. I think the switching regulators should be overkill, but at least fun to play with.
We'll see how it goes.
Posted 2010-03-03.
Python is the new BASIC
This is not an original blog post title. Others have said the same thing, followed by a post body saying 'but I don't mean that in a disparaging way'. Let's get one thing clear. I mean this in a disparaging way.
Ok, it is a good beginner's language. And unlike Dijkstra thought about BASIC, you can learn it as your first language, and you won't be scarred forever (just like BASIC). However, you will eventually need to move on from this language and be rehabilitated into society before you can be fixed up. You need to acknowledge that it's not a real language, and so few Python programmers admit this. :p
The problems I have with the language are, basically, that it's a dynamically-typed grab bag of ideas from all over the place. So, its core design isn't particularly coherent. As the ideas were copied without real understanding, they're done wrong, and there are unpleasant bodges. Dynamic typing means there are whole classes of error you can pointlessly leave in, waiting for the appropriate runtime failure. Yeah, you can do insane amounts of testing and run other tools, but... a solid, static type-check from the get go is just so much cleaner and safer. And that matters.
The problems I have with Python programmers is that they think they know something. The language is neither low-level, nor cutting edge. It doesn't show you the hardware, or bring you to neat theory. It just gets the job done, and because it's so pragmatic, it gets the job done badly. So Python programmers, having chosen this particular sub-optimal point in the space of programming languages for themselves, are either ignorant or deluded.
(I'm still programming Haskell for my day job. It's an impractical and basically ludicrous language. However, the right language doesn't exist, and it certainly doesn't have an excellent compiler and set of libraries. In the meantime, I love Haskell.)
Posted 2009-12-22.
Finding bugs in the GHC runtime
Race conditions are always a pain. We just spent the better part of two days tracking down a race condition which caused our production executables to hang once in every few thousand invocations. Surprisingly, it wasn't the normal DllMain deadlock.
On the other hand, it was a nice excuse to play with WinDbg and binary patches.
See GHC Trac for details.
Posted 2009-12-12.
Magnetic Scrolls
My Project Euler addiction has been effectively destroyed by taking away my mathemtical ability. A new baby has had that effect on me. But I still have a puzzle urge and time between feeds. So, I've been looking at the old Magnetic Scrolls text adventures. I tried Fish! and Guild of Thieves nearly 20 years ago, but never really got very far, so I was intrigued about having another go. Jinxster looked like a lot of fun, so I had a go...
And generally, it was! As with so many adventure games of the era, it's unforgiving and pedantic. You have to spell things out, and if you make a mistake it'll let you keep playing even though you can't play to completion. Having said that, it's friendly as far as the genre goes. In-game characters sometimes provide subtle hints, and the structure of the game allows progress even if you're stuck on one puzzle.
On the whole, the puzzles are rewarding. Initially, I thought there were a number of evil red herrings in the game, but it looks like a number of puzzles can be solved multiple ways! I'm almost proud of myself. I made it through the whole game except the last puzzle without spoilers. When I read the spoiler for the final puzzle, it basically told me how to do what I was already trying to do. *sigh*
In fact, I found the whole ending section disappointing. The last puzzle was put together slightly shoddily, and the ending might have tried to be a clever twist but... no thanks. It's a shame, really, as I rather enjoyed the game as a whole. I may have to play another.
Posted 2009-12-07.
David Alexander Frankau
Having now announced this to most of our friends directly, this is now unembargo'd!
Caroline and I are delighted to announce the safe arrival of baby David Alexander Frankau, who was delivered safely at home at 8.04am on Friday 30th October 2009. He weighed 7 pounds 11 ounces at birth and is, in the opinion of his completely unbiased parents, the cutest baby ever!
Posted 2009-11-11.
Fun with pipes on Win32 (3)
So far I've talked about the irritation I was seeing on the C++/Win32 parent process side. However, we also saw weirdness on the Haskell side. Everything is done inside a System.Timeout.timeout call, so that the process really should never wedge. The parent process, being buggy, was doing a blocking read on stdout. The child process was writing to stderr. We saw weird behaviour:
- If less than 4096 bytes are written, the pipe does not block. The process shuts down, the parent process finishes its read of stdout, and reads the buffered part of stderr. All's good.
- Between 4097 and 4608 bytes, the process hangs.
- More than 4608 bytes, the process times out.
The first piece of behaviour is expected... but what's going on in the other two cases? In the last case, the OS buffer is filled, the write call blocks, and as the write is inside the timeout block the timeout occurs. We might expect this, but why only over 4608 bytes? Haskell internally buffers 512 byte blocks. So, if you write over 4608 bytes, it'll fill up the internal buffer 9 times, write out 4096 bytes (to fill the OS buffer), and then trigger a final write, inside the 'timeout' block. The process times out.
Between 4097 and 4608 bytes, the internal buffer will be drained 8 times, writing out 4096 bytes to the OS, and filling its pipe, but leaving the internal non-empty. We leave the 'timeout' block, and start to shut the process down. Our stderr internal buffer needs flushing, so we perform a blocking write, this time outside the 'timeout' block. Deadlock.
What's the upshot of this? If you want to know what's going on, you need to understand the details of your system, as abstractions leak. Oh, and if you want 'timeout' to work quite as you expect, you might want to flush your handles before the end of the block.
Posted 2009-09-15.
Fun with pipes on Win32 (2)
Previously, we'd moved from using anonymous pipes to communicate with our subprocess, to named pipes with unique names. Problem solved, right? Sadly not!
Rather than create completely unique names, I created names that were guaranteed to be unique for the lifetime of the sub-process. Generating totally unique names just seemed like overkill! So, I create one sub-process, then the next one, and use the same unique pipe name each time. As long as the sub-process has died, and the parent's end of the pipes are closed, the old pipe will go away, and a new pipe with the same name can be created.
Furthermore, our sub-process manager is multi-threaded. So, we can fire off multiple sub-proceses at the same time. However, the pipes weren't being closed properly (so we couldn't reuse the names) when run in multi-threaded mode. Why?
It's all to do with the way Win32 passes handles to sub-processes. In order to get a handle into a sub-process, we have to make the handle inheritable, and then spawn the sub-process with 'inherit all inheritable handles'. Unfortunately, if you spawn two subprocesses around the same time, both children will inherit the handles (even if they're not wired up to stdin/out/err in that particular process). So, the other process is holding the pipe open.
We can reduce the window by closing the pipe as soon as the sub-process is fired off, but the race is still there. We could then hold a lock during the spawn step, but it's slightly icky to introduce the extra synchronisation. Personally, I think it'd have been nice to control exactly which handles are passed to which subprocess, but this looks like a weakness of the Win32 API. Unix-style APIs, using fork/exec allow you to control the exact handle (file descriptor) set-up for the child. Gah.
Another funkier approach that I didn't try is to spawn the sub-process suspended, use DuplicateHandle to poke the handles into the sub-process, and then unsuspend the process, to spawn a subprocess with exactly the handles required.
So what did I do? I just made the pipe names globally unique.
Posted 2009-09-15.
Fun with pipes on Win32 (1)
Most of my work nowadays is writing Haskell, but to interop with other systems we have COM server which fires off the Haskell processes and communicates with them through pipes - we could do things less indirectly, but this is a nice, simple way of decoupling the components. However, the pipes have been really quite irritating to deal with.
First off, Win32 anonymous pipes (the kind of pipes you'd expect to use to communicate with a child process) don't support WaitForMultipleObjects. This is really quite irritating if you want to support select-style reading from your sub-process. Why might you want to do this? Well, the alternatives are:
- Just do blocking I/O. Except if you're reading from stdout and stderr on the sub-process, if you're blocking on one handle, and the child process writes a pipe's-worth to the other handle, you have deadlock.
- Do a polling loop, non-blocking reading one, then the other, with a little sleep inbetween. This is no solution, I'm just mentioning it because it's such a bad idea.
- Fire off an extra thread or two, just to blocking read the handles. Yuck, yuck, yuck. All the extra set-up of starting heavyweight threads, with a meg or so of address space, makes this heavy and unscalable (ok, there's plenty of overhead in starting a subprocess, but it's the principle!).
So, instead I tried WaitForMultipleObjects-ing on the handle. MSDN said I couldn't, but MSDN lies about lots of stuff. It turns out MSDN was telling the truth, although it wasn't immediately obvious. It basically immediately returns (without error), so we then perform a blocking read on the pipe, leading to the deadlock described above, as we wait to read one pipe, and the child waits to write the other.
The solution? Use named pipes, with unique names. This link contains the basic source, which you may want to adjust for your personal use, while complaining that the Win32 API really should do this right itself, especially since it's such a common usage case.
Posted 2009-09-15.
I own a Nokia 2630.
This is a rubbish phone. Fundamentally, the call quality is shocking. I assume the aerial is rubbish. The user interface lags - I push a button and have to wait to see something happen. I reckon there's a half-second lag betwen me hitting the keys, and the phone actually locking or unlocking, and ditto for most other operations. I previously had a 6230, and while it had its foibles, at least the text went in as you typed it, the keypad had less inconvenient buttons, and resuming an interrupted text was super-simple. How, given fewer constraints than previous generations, they've managed to make the interface worse, I do not know.
In fact, I only discovered how to change the volume on this thing today, thanks to googling, as I felt so silly being unable to do that. Left and right directional keys during a phone conversation, apparently. Makes me realise how much I liked dedicated volume keys. Even my 3210 used up and down, I think.
This is my fourth Nokia phone, as I've generally found them consistent and straightforward. Oh, and apparently they've had good sound quality, 'cos in comparison, this thing's rubbish. I try to choose simple, small phones, 'cos all I want to do is keep it in my pocket (small) and make calls and send texts (simple). So, I got this simple cheapo phone. It does admittedly deliver on the small side, but given it doesn't actually make phone calls very well, I should probably just keep my pocket empty instead.
I have a suspicion that they could make a cheap, high-quality phone, but they'd rather make their low-end model rubbish, to encourage you to upgrade. After all, they couldn't deliberately design something as bad as this, could they?
Posted 2009-03-15.
We had a skiing holiday
Not particularly exciting for anyone who wasn't present, but I enjoyed this sufficiently to talk to anyone who'll listen to me about it. Caroline and I went on holiday to Courchevel with a couple of friends. Caroline doesn't ski, and so hung around and absorbed the ambience. I went on the slopes and just massively enjoyed it. We were last in the area a couple of years ago (La Tania last time, 1850 this year), and at the time I did one red run and was petrified. This time we spent most of our time on the reds, and it really opened the place up and was just so much fun that I have a giant grin on my face writing about this, just thinking about it.
Outside of the skiing, our gap-yearing chalet host was fantastic, and our friends' toddler upped the cute factor (so glad I didn't have to play any role of responsibility, though ;). A wonderful break. But gosh, Courchevel's expensive!
Posted 2009-03-14.
I'm going to have a paper published!
For the first time in years, I'm going to have a paper published ("Going Functional on Exotic Trades" in the Journal of Functional Programming), which is remarkably pleasant. It's my day-job in paper form, and it's mentioned at the bottom of my now-recently-updated research web page. Yays.
Posted 2008-12-10.
The C++ Standards Committee Hate Me
This is the only possible reason I can think of for the fact that the default "precision" value for an ostream is 6. What does this mean? It means that any floating-point number it prints out will be rounded to 6 significant digits.
What?! Why?! Let's put this into perspective. A double-precision floating-point number commonly has a 56-bit mantissa. Let's be generous, and say that each decimal place requires 4 bits to represent it. We'll even ignore the hidden bit. That's still 14 digits. Even if you then go and assume that your calculations have destroyed half the precision, pretty much a worst case unless you're either doing something wrong or are in hardcore numerical-analysis land, that's still 7 significant figures. And that's a very generous worst-case analysis.
Let's look at it another way. 32-bit ints go to 10 significant figures. They can be stored exactly in normal doubles. They can be printed directly, and that's fine, but if you cast them through a double first, the default will truncate them when you print them.
I have a program that reads in numbers and prints them out again. I assumed sensible defaults for precision. I lost. I have had to fix the precision on my ostreams before writing to them, and I have no idea why. I'm sure there are situations where 6 significant figures are what you want. On the other hand, I would very much like it if that were something you had to select, and the defaults weren't incredibly stupid for default use.
Pah.
Posted 2008-12-07.
Rules of thumb in writing code
There are a number of rules of thumb when writing code. Things that are generally accepted as good style and ways to work. You know, things like employing abstraction and making stuff data-driven. What they don't tell you is that there's too much of a good thing. This is patently obvious - you can always make things more data driven by adding an extra interpreter, and you can always stick more wrappers in for 'abstraction'. Put another way, you're trying to find a maxima of style in program space, and this isn't going to happen by heading traipsing off to infinity.
They're called 'design decisions' for a reason. There's a decision to be made. You can't hide behind just doing commonly accepted 'good' things. If you do that, you're going to end up producing 'enterprise' code which runs around in circles, reinvents all kinds of wheels and/or pulls in every library you can think of, bloats out to infinity, and is still a complete pain to actually maintain. And then I have to review the code and explain what's wrong. And guess what? Every single decision will get justified as doing what is commonly accepted as good practice. *sigh*
Posted 2008-09-12.
On Rewriting Code
This note is somewhat bitter. It's about the software event horizon, beyond which a piece of software sucks and there is nothing you can do about it. It's something I encountered a couple of years ago, so hopefully it's far enough away, and I've filed off all the serial numbers. It was in another team. And besides, the project is dead.
It has been claimed that the single worst mistake you can make you can make on a big software project is to rewrite it from scratch. On the other hand, I believe there are situations where the best thing you can do is to throw it all away and start again. Presumably, these two situations are distinct, and the sign of an experienced developer is one who can choose the best course?
No. Sometimes, the code base is just screwed. It's dead, and you don't know it yet. You can rewrite from scratch, and it'll fail. You can maintain the existing code, and it'll just bog down and become a programmer trap, a developer black hole. In retrospect, you'll say you should have done the other thing.
However, you're just in a no-win situation. What can you do? Well, often it's not actually that bad. It'll be painful, but you can start retrofitting test harnesses, decoupling components, and pull the code base back to something where sensible decisions can be made. However, if your code has plenty of race conditions, relies on 'strategic leaks' and generally has bodge upon bodge upon bodge, it may be a no-hoper. I suggest firing the management involved for letting it get into this situation. Then fire their management for letting them do that. For bonus points, trawl through the source control logs for the very worst bugs introduced, and put the developers involved on the 'do not rehire' list (obviously they won't still be with you - such a project requires high turnover).
In summary, the best thing to do is to steer clear of such projects. For some reason, no-one believes it can be that screwed up, so whatever you do people will be unimpressed. Run away from a zombie code base while there's still time!
Posted 2008-07-29.
Yellow Peril
I made a hideous discovery in Heffers, the Cambridge bookshop, just before I got married: The Springer Yellow Sale. A very dangerous event for the wallets of wannabe mathematicians. In the Yellow Sale, plenty of Springer maths books are pretty much half price. This reduces them from eye-wateringly expensive down to just plain expensive. Who can resist half-price introductions to p-adic numbers? Suffice to say that, despite my already huge maths book backlog, I've now got a few more lined up. Ho hum. I'm weak. Sale ends at the end of July!
Posted 2008-07-26.
Protocol Buffers
You may well have heard of Google's Protocol Buffers, the latest and trendiest way to treat everything as a nail. The logic goes something like this: XML is complicated, verbose, expensive to process and ubiquitous. So, let's use something completely different for everything instead!
What's XML good for? It's a decent representation of structured data. So, we get to use it as an insane way of writing RPC requests and obfuscating data better put in a CSV file. Oh, and serialising objects. This is all obviously rubbish, and Google's protocol buffers will solve everything. Until we realise the weaknesses of the new format, that is.
What might be nice is if people actually applied sensible tools for the job, and didn't conflate different requirements. Protocol buffers are a lightweight IDL implementation, so it's probably best to use it for that. Use it to generate RPC requests. Maybe use it for inter-language communication of data-structures, and limited persistence.
Then notice that protocol buffers aren't self-describing, aren't easily human readable or editable, and things like that. Note that you might want to use JSON or even XML for appropriate situations. CSV maybe. And notice that object serialisation (as opposed to data structure serialisation) is something you don't want to conflate with other stuff, because if you do it'll become some kind of interface, and if you're really unlucky people will be editing the serialised structures by hand, and it's all a mess.
Please. Use the right tool for the job.
Posted 2008-07-26.
Fun with CoLoadLibrary
This is for the 3 other people in the world still using COM.
We're writing a 'front-end' COM server which wants to delegate work to back-end DLLs. Specifically, it will load up a DLL and pull out an object with the appropriate interface. It sidesteps CoCreateInstance, so we avoid lots of painful registry look-ups when we know exactly which server we want to implement the thing. Why would we do this? Because it allows us to supply our own version of DLL hell, rather than the COM-server-registration one which comes free as standard.
So, is all light and fluffy? Not quite. Normal COM object creation gives you appropriate cross-apartment marshalling and proper DLL unloading. The marshalling isn't a problem - the newly created object just ends up living in the same apartment as the loader object. What about DLL unloading? COM normally allows libraries loaded for the sake of accessing COM servers to be unloaded after a period of unuse through CoFreeUnusedLibraries(Ex). So, if COM didn't load our library, it won't unload it. Argh.
What's specifically the problem? Suppose we have a COM server in the back-end with instances still alive in it. Then it can't be unloaded. Moreover, it can't unload itself when the last instance goes away (FreeLibraryAndExitThread being the nearest thing, but with nasty race conditions). The only thing that knows it needs unloading, and that can unload it, is the front-end library which LoadLibrary'd the back-end. So, this thing must be prevented from unloading until all the back-ends have disappeared.
It looks a mess, since the loaded DLL has to somehow inform the front-end when it's done with, so that the front-end can unload it, and in turn be allowed to unload. Quite a faff. Why can't we just tell COM to unload the back-end for us when all the objects are gone?
Back in the day there was CoLoadLibrary, which had an 'AutoFree' parameter, which did just that. COM would take control of the unloading of the DLL at the appropriate point. Except... it no longer works. MSDN helpfully notes this, after explaining how it would work if it did. In practice, no error is raised if you use this flag. Effectively, it just silently leaks the DLL.
So, how did the COM unloading mechanism work anyway? It calls DllCanUnloadNow on all the COM servers loaded through CoCreateInstance, and on any that return true, it then unloads the DLLs. In the end we just used this mechanism to fake up the COM unloading system. COM would ask our front-end DLL if it could unload, and this would trigger a cascade of DllCanUnloadNows on the back-end DLLs. If they could be unloaded, they got unloaded, and our front-end DLL finally gets unloaded only if it's supporting no objects, and all the libraries it loaded are now unloaded.
It works, but WHY OH WHY COULDN'T THEY JUST LEAVE POOR COLOADLIBRARY ALONE?
Posted 2008-07-23.
On the Naming of Climbing Shoes
In an attempt to improve my health, I'm trying to get a bit more exercise. Specifically, I'm trying to take up climbing (we'll see if I keep it up). Since rental shoes are, er, pretty grim, I bought myself some climbing shoes. I got them from Rock On at Craggy Island, the climbing centre in Guildford. I recommend both the centre and the shop to beginners. I can't tell if the guy in the shop was actually knowledgable, as I'm a novice, but he did a very good impression and was very helpful!
But what shoes did I get? I got a pair of 'Ballet "Gold"'. Yes. The quotes are in the name. I checked, and they are men's shoes. I love the combination of macho-ness and class that comes from combining the word 'ballet' with a precious metal in quotes. Presumably they feared that if they didn't use the quotes someone would sue them for the lack of valuable metals. Taking this line of reason, I assume it must actually be possible to do ballet in these shoes, although it does seem unlikely.
In short, I suspect the marketing department involved do not speak English.
Posted 2008-07-20.
Best Art For Under 10 Grand
We went to the Royal Academy Summer Exhibition the other week. It was rather good, although we didn't come away with anything (some of the works are fairly cheap, and pretty good, but nothing affordable really connected with us). However, it did give us a chance to find a few artists which we really rather liked. So:
- Bryan Kneale Mostly known as a sculptor, Caroline rather took a fancy to his drawings.
- Oliver Akers Douglas Another one Caroline liked.
- Paul Emsley Kinda stunning.
- Karn Holly Super-atmospheric.
- Lynne Collins Unlikely photos.
Disqualified on price were Ken Howard and David Tindle.
When we win the National Lottery, these guys better beware.
Posted 2008-07-07.
Wedded!
Caroline and I are now married! We got married at St. John's College chapel, Cambridge on 7 June, and have just returned from a little honeymoon in the middle of nowhere. While we have tonnes to say on the subject, I think we'll leave it at that for the moment!
Posted 2008-06-13.