Simon Frankau's blog
Ugh. I've always hated the word 'blog'. In any case, this is a chronologically ordered selection of my ramblings.
Lego Mindstorms is Trigger's Broom
Lego is not quite Trigger's Broom, or rather the name is, but the toy itself is not. Lego Mindstorms shares the name with the original toy, but is basically incompatible, having been incrementally redesigned over the years.
So, I've been out of Lego for well, most of twenty years - a generation - and am getting back into it with my children. I received a fantastic Lego Mindstorms set as my leaving present from my last job, and decided to build it with them, which meant waiting for the Summer holidays. The holidays have arrived, and we're now playing with it.
It took a while to realise it, but, well, look at the pieces:

The top piece is traditional old-school Lego. The bumps on top allow you to stack pieces. Good in compression, poor in tension. The second row is Lego Technic from my childhood - the holes can hold axles, or rivet-like pieces to bind the bricks together, like a spanner-less Meccano. The third row is Lego Mindstorms - it's got the holes, but it's got no bumps. You can't directly use old-school Lego with Mindstorms!
I can kind of understand why they did this - the traditional Lego connections, being poor in tension, are useless for the kinds of applications Mindstorms are for. On the other hand, it seems really weird to have a Lego-branded product that, well, doesn't plug with Lego.
Posted 2015-07-25.
A painted cube
A friend said I should paint the 3D-printed Weighted Companion Cube, so I did. I had the paints left over from a model kit from my childhood (see previous post), but I'd never really used them before, especially on something small. For some inexplicable reason I hadn't spent my early adolescence painting tiny model orcs, so the painting was something of a lesson for me. I learnt:
- Twenty-year-old model paints work fine.
- A loupe is really useful.
- I would have been better off giving it a comprehensive base-coat of white at the start. The grey shows through pretty easily, made worse by the bumpy surface (see below).
- Working at a tiny scale is very fiddly, but with a super-pointy brush previous experience playing at watch-making came in useful.
- It's really fiddly.
- At this scale, the printing ridges are large. It really does want to be smoothed down (acetone trick?) before being painted.
- It takes far too long to do.
Without further ado, the fruits of this labour are below. To be honest, I reckon it looks a bit better in real life. :)

Posted 2015-07-19.
Constructing things (planes and cubes)
Recently, I've been constructing things. A few months ago, between jobs, I popped down to where I grew up to collect the last of my stuff. It's been some time! However, I didn't really want to pull things out until we'd bought a place, to avoid moving everything time and again. Then, when we'd bought a house, time for this kind of thing was incredibly limited. Anyway, the stuff's finally here.
Amongst all this stuff was a balsa-wood model aeroplane that I was constructing with my father, a project that must have stalled in the early '90s, if not before. The fuselage had been glued up, but that was it. Being something of a completionist, I worked through the rest, and it's now ready to paint!

It's not a brilliant job, but it makes me happy. Things I discovered include:
- Assembly of the balsa wood frame is quite rewarding - cutting the balsa is simple, balsa glue is unyucky and wonderfully quick setting, and you can build up a shape fairly easily.
- Covering with tissue paper is a PITA. I avoided traditional dope, going instead for PVA glue, which seems to make a nice substitute. Covering the fuselage in small pieces was incredibly tedious, but simple and the result wasn't bad. Covering the wings was a right faff. This is also, I think, where dope may have an advantage, since I think it can help tighten up the paper on the wings. Instead, the paper is not exactly taut on my model.
- It was also not clear how to deal with the edges of the paper - do I go for sharp edges and a little bump, or something a bit more torn in order to try to smoothly transition? You can see the dots on the leading edge of the wing where my scalpeling did not go to plan.
- A 3D printer comes in handy - those wheels were printed and painted, as one of the original wheels in the kit was lost over the decades.
"A 3D printer?" you say? Why, conveniently work has a 3D printer for our use, which looks like an extremely fun toy. It has the advantage that you can set it off, go do some proper work, and then come back when the print is done.
My first test was a Weighted Companion Cube, because I'm a fan of Portal. My first attempt went wrong when I failed to click the "add supports" button, leading to the printer attempting to doodle into space. One quick cancel later, and a reslice, it was off. With a well set-up high-end consumer printer, printing a small part, it seems that the whole thing's near idiot-proof.
This is the result. It's about an inch cubed:

To my eyes, the quality is very good. You can see the printing artefacts, but they're relatively small. I am extremely tempted to try the acetone vapour smoothing trick, and see how it goes.
Posted 2015-07-19.
Solving Rubik's Magic: Master Edition, Part 2: End game
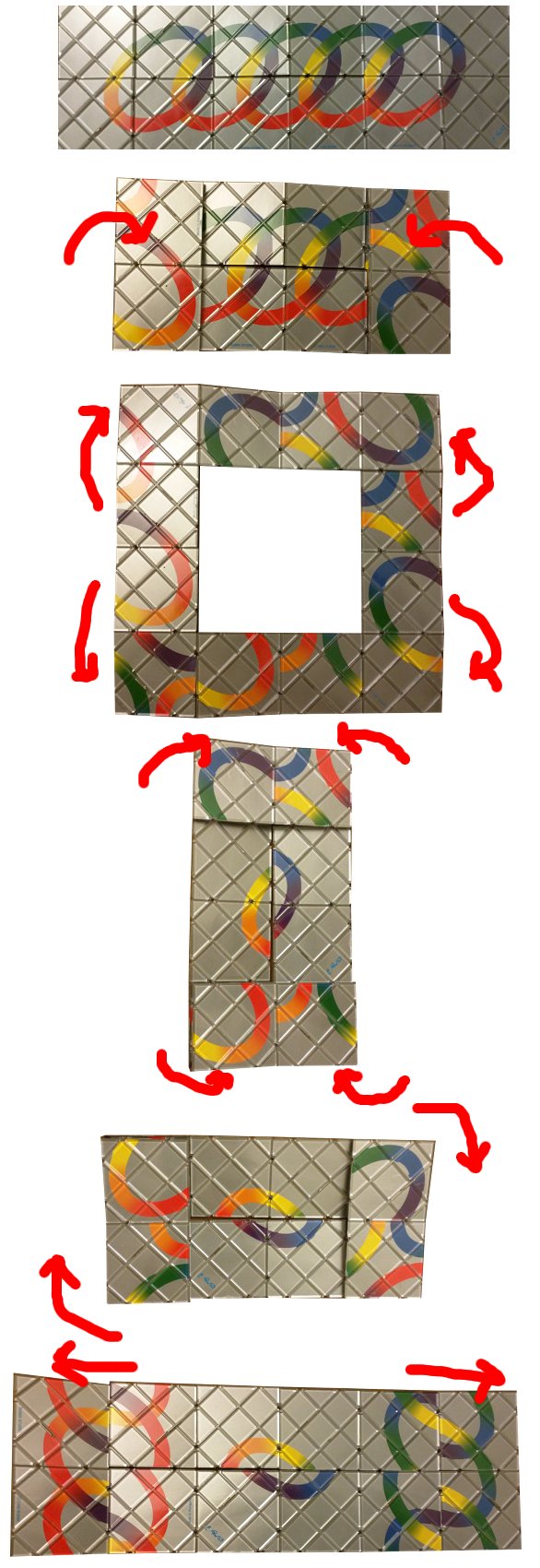
Finally, the solution! This stage involves some moves that are relatively tricky to explain, and if I were living on the cutting edge of ten years ago, I'd just attach a video of the moves. As it is, I won't, and instead I'll find someone else's description.
As it turns out, after exploring the complete space of 2x6 configurations, the only move required to get to a state from which we can solve the Master Edition is a "-X". This takes us from the initial back view:

To a configuration where you can see the core of the solved puzzles:

From here, you can perform a twist very similar to that used when solving the small magic, to move to an "L" shape:

Finally, you can do two of the "bend the corner round" moves that you use to finiah the small magic, to bring it into its final configuration:

I found the website in the links after writing everything else up, when I was looking for an easier explanation of the more complicated moves. Interestingly enough, the moves described there are basically the same set, plus a "row swap transform", which it describes as also implementable with X and O. So, it appears my analysis is either "unoriginal" or "correct", depending on how you look at it.
Posted 2015-07-05.
Solving Rubik's Magic: Master Edition, Part 1: Group theory
In this post, I'm going to look at moving between the possible 6x2 flat configurations. For everything here, I'm assuming that you're viewing the Magic joined-up-rings-(starting position)-side-up. As the pattern's a bit distracting, I'll be using a schematic view of the Magic:
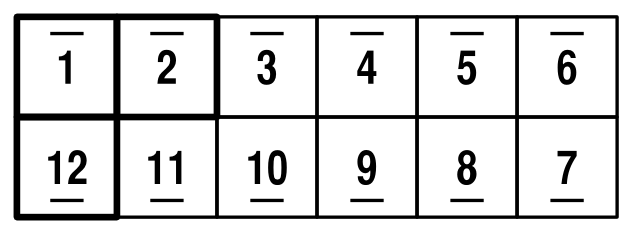
The numbers represent the position of squares initially, and the dots represent a particular edge. Initially, I'll place the dots on the outside, have the top-left square be square number 1. Note that the 3 highlighted squares in the top left more than define the position of everything else (see my previous post for details).
We're going to see what positions are reachable given combinations of three basic moves. The first, I'll call "X", after the way the squares windmill, and it's simply achieved by folding the Magic up, folding one square down, and another up:

X simply moves all the pieces around one step, without any rotation or fancy changes:
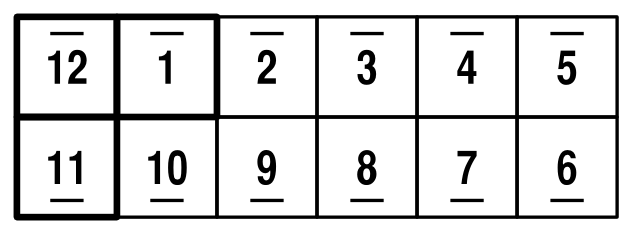
The next move, I'm going to call "O", since we make the Magic into a loop. Just fold the Magic in half, then slink it one square along. Note that it will then open up the other way:

So, this move can be used to change the orientation of the pieces:
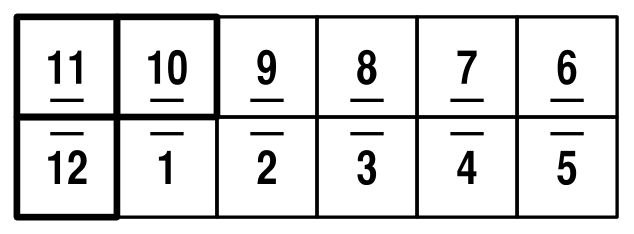
Note that so far, we can only rotate a piece by 180 degrees. Next move, I'll call "S" for "square", as we do a move that makes it into a square, then unfold it again (90 degrees around) to end up in a different shape:
This move rearranges stuff quite a bit, and includes a quarter turn, which should allow us to reach more configurations:
So, given these basic moves, can we create all configurations? Well, we can if we can move any piece number to the top left, rotate it arbitrarily and switch between clockwise and anti-clockwise numbering...
- Moving a piece to the top left Simply do "X" repeatedly.
- Rotate the top-left piece S, -X, -X, -X (-X being the undoing of an X move).
- Change direction of loop O, X, X (also rotates the top-left piece by 180 degrees, but you can fix that by doing the rotate step twice).
Given this, we can make any 6x12 configuration, so as long as we can go from a 6x12 to the final "W" shape, we can solve the puzzle. And that's the next post.
Posted 2015-07-04.
Solving Rubik's Magic: Master Edition, Part 0: Counting configurations
This is old, old news to everyone but me. Growing up, I loved my Rubik's Magic, but I never played with the Master Edition. Moreover, I never tried to analyse it mathematically. So, I decided to finally play the thing, and try to understand it.
Solving it wasn't difficult, but getting around to writing it up has been a right pain. :) I thought I'd start with something very simple: Counting the number of configurations. Specifically, the number of 2x6 flat, rectangular configurations (like the starting position).

First a couple of fairly obvious constraints: Whenever the puzzle is laid flat, it's always with the same set of pieces facing up - there are two "sides", and pieces don't move between the sides. Moreover, each piece is always connected to the same other two pieces - the sequence of pieces in the loop is always the same.
So, we lay it flat in front of us. We can choose either side to face up. There are twelve possible pieces that can go in the top left. This piece can be one of four rotations. That fully describes the configuration of the top-left piece.
What about everything else? The neighbouring pieces will always be the same, due to the limitations of the "loop". However, this loop could be running clockwise or anti-clockwise. However, once that's determined, everything else is determined. The orientation of all the other pieces are full determined by the orientation of the top-left piece - as it rotates, all the others rotate, like gears.
This gives us 12 x 4 x 2 = 96 configurations. However, the puzzle itself has a rotational symmetry of a half-turn, so really that's just 48 configurations. This is far fewer than I was expecting! By similar logic, there should be 32 configurations for the vanilla magic.
This assumes, of course, that all the configurations are reachable - this is an upper bound, but perhaps some configurations can't actually be achieved. As it turns out, all the configurations are reachable, and that's what I plan to demonstrate next time...
Posted 2015-06-28.
Two Weeks of Google and a new phone
So, I've been two weeks at Google, and one side effect I hadn't really noticed before is that my own home projects are getting somewhat sidelined by the fire hose of learning new stuff at work. Ho hum.
On the other hand, I've got a fancy new work phone.

It's a bit bigger than the last phone I had.
On the other hand, the technology's moved on tremendously, and it's really nice to be browsing the web on a mobile without feeling like a second-class citizen. The downside is moving over to the Android ecosystem is faff. The apps are ok, but moving my music and photos over is a pain. Still, slowly getting there...
Posted 2015-06-17.
One Week of Google
One week of Google, and it really is as people expect. I've learnt a whole pile of cool stuff, but as described in How Google Works, there is much internal transparency, but leaks are taken extremely seriously. So, I'm not going to reveal pretty much anything. Oh, and memegen is as silly as the book makes out.
5/5. Would be recruited by again.
Posted 2015-06-06.
Paper round: And then some
I may have finally written up the papers I read some time ago, but I still have a number of papers from that pile, plus a couple more recently-added ones. Time to discuss them:
- Mosh: An Interactive Remote Shell for Mobile Clients This paper reminds me how I don't tend to take an innovative approach. I thought of ssh as good enough, and am generally suspicious of reinventing the TCP wheel. Then, this paper shows how you can make remoting over flakey wireless connections much better if you try. D'oh. ("mosh" itself is rather nice, but I'd really rather like good scrollback.)
- Practical Byzantine Fault Tolerance One of the classic papers on distributed systems. The bit on committing operations is very plausible, but I look at the section on changing views and... its correctness is not intuitive to me. Tricky.
- Data Compression Using Long Common Strings Data compression is often rather tricky, but as you might expect from Bentley and McIlroy, this is both simple and effective. Fun.
- Large-scale cluster management at Google with Borg And this one suddenly looks very relevant to my work! The first section or two seemed a bit vague and naff, but the details fill in over the later sections to give a reasonable impression of what they had and now have. The future work section (especially Kubernetes) looks very interesting, and the references should give me plenty to chew on.
- Breakthrough silicon scanning discovers backdoor in miliary chip A somewhat melodramatic title sits at the top of a fundamentally unremarkable paper. Unremarkable, perhaps, but still fun. The "backdoor" is in an FPGA used in, among other things, military technology, allowing the bitstream to be read out. Looks like an undocumented debug feature. The interesting things are a) how the advertising material lies so strongly about the security b) the technology used to identify the undocumented feature.
- Trafficking Fraudulent Accounts: The Role of the Underground Market in Twitter Spam and Abuse Yet another fun little paper investigating the online criminal economy. (If you like this, go read all the Silk Road reporting - not directly related, but also interesting.)
- TCP ex Machina: Computer-Generated Congestion Control Another paper by the guy who did Mosh, although I came across this one first. In short, by applying a simulate-and-optimise approach to TCP congestion control, something can be produced which appears to work rather better than standard (human-designed) congestion control algorithms. There's lots of interesting stuff here. Is the evaluation biased by the fact that it's using models not entirely dissimilar to the ones used to do the optimisation, leading to over-fitting? Can we know it's not going to have horrible corner cases because it's not human-designed? When setting up an optimisation problem, how the problem is framed will feed into the result, and that's rather interesting. For example, packet loss is not used. Instead, RTT variation is used to detect queuing, which is rather nice given the problem of buffer bloat. All rather cool.
Posted 2015-05-31.
Paper round: Odds and ends
Around, er, two years ago, I reviewed a bunch of papers, and noted some other topics I should learn more about. I read up on some of those topics shortly afterwards, but never actually put together a round of paper reviews covering highlights of what I'd read since then. This is it. There are a lot fewer papers than I should have read, but on the other hand, there's a lot of cool stuff that's just readable as web pages now, so I almost feel less embarassed about it...
Data structure and algorithms
- A Digital Signature Based on a Conventional Encryption Function - Merkle This is the origin of Merkle trees (hash trees). The hash tree idea is rather useful in many situations, but it's really not a huge part of the paper, which is another clever crypto algorithm paper. Fun, but less relevant than you'd expect for hash trees.
- "Hash tree" in Wikipedia I'm reviewing Wikipedia pages now?! Apparently. Anyway, a much more useful introduction to hash trees than the above paper, even if it misses out fun irrelevant crypto.
- "Error detection and correction" in Wikipedia While I'm at it, error detection/correction codes are nutty, and I've never found a decent introduction to them. On the other hand, reading a few Wikipedia pages is actually quite a good way to get a basic idea of the landscape. I also read the pages on Erasure Code, and Turbo Code. Turbo codes are nutty magic. I need to read a proper book on codes.
- Turbo Codes - Emilia Kaesper Another introduction to turbo codes. It explains how they work, but doesn't give a good intuition as to why they work. They continue to be magic to me.
- Space/Time Trade-offs in Hash Coding with Allowable Errors - Bloom Bloom filters are awesome, and I'm embarassed I didn't know about them sooner. They should have been somewhere on my undergrad algorithms course. This paper introduces them. Read it.
- The Log-structured Merge-tree - O'Neil et al The LSM-tree is basically "Keep multiple copies of the data in a hierarchy (e.g. in-memory and on-disk), and then batch up and merge through, to allow high-throughput writing with querying." The paper is, I thought, disappointing - long-winded and not terribly inspiring.
- Consistent Hashing and Random Trees: Distributed Caching Protocols for Relieving Hot Spots on the World Wide Web Ugh. An ugly long paper title, presumably influenced by "it must be a trendy web technology". This paper covers consistent hashing and random trees, but it's only really consistent hashing that I wanted to learn about. The paper hides the intuition behind it pretty badly compared to, say, the Wikipedia page.
Google papers
I'd previously read about GFS, Bigtable etc., as well as Dynamo and a few others, but there were plenty more Google papers to read. Bear in mind I read these a couple of years before my Google start date:
- Spanner: Google's Globally-Distributed Database This is Google's replacement for the famous BigTable and Megastore systems. You can tell it's a big deal by the number of authors on the paper! Sadly, however, I don't get the big deal. There appear to be two impressive angles: The timing aspect, and SQL-like querying. The timing aspect seems mildly unimpressive to me - if you synchronise your clocks, you can bound when each component sees things. Er, great. And the SQL-like querying angle isn't really covered by the paper. So, the level of innovation, as presented by the paper, underwhelmed me. Ho hum.
- Experience Report: Haskell as a Reagent - Pop Having used Haskell for a production system, I had some interest in seeing how other people ended up using it. In the end, I found the paper a little unexciting, but competent enough. Oh, and Haskell was being integrated with Python. Ick. Since reading the paper, I've become a little more interested in sysadmin approaches at Google. Ahem.
- A New ELF Linker - Taylor This describes the "gold" linker. Pretty cool work by the guy who worked on the original GNU "ld".
- Modular Software Upgrades for Distributed Systems - Ajmani et al Another Google one. Basically "How do you upgrade complex, long-lived distributed systems?" "Carefully." Nice ideas, but just a little more formalisation than was really necessary.
Misc
- The Athens Affair (IEEE Spectrum) Co-authored by a co-author of the FPF paper (the rather prolific Diomidis Spinellis), it's a discussion of the rather fascinating hack of a Greek cell-phone network. It's one of the lesser-known publicly-known probably-sponsored-by-the-US hacks.
- Barbarians at the Gateways - ACM Queue An introductory article on the HFT arms race and the technology it involves. Light fun.
- Finding and Understanding Bugs in C Compilers - Yang et al Generate randomised test code for compilers, compile them, look for bugs. Collect bugs, fix them, look for patterns. Really quite interesting.
Posted 2015-05-27.
Tobin/Transaction taxes
I am, I'm afraid, now on Twitter. I read it for the links to articles, you know. Anyway, I saw this Tweet retweeted by people that I know (and generally think of as sane):
A Robin Hood Tax is a tiny 0.05% tax on transactions in the financial sector. This could raise 20 BILLION GBP a year. RT if you support this.
To me, this illustrates perfectly why anything even vaguely subtle shouldn't be discussed on Twitter. Fortunately, the Wikipedia entry on Tobin taxes does have a lot of detail. It's a bit long. I thought I'd do my take on it, even though I don't have a Nobel prize in economics (yes, I know it's not a real Nobel anyway).
I've just left a job in the finance industry after ten years, so I think I have a reasonable understanding of it, without having a huge investment in its future.
The size
First of all, I'm not sure how a tiny tax can raise mind-boggling amounts, unless because it's not a tiny tax, but actually a huge tax, pretending to be tiny. To put the twenty billion in perspective (using slightly old data), the UK's finance industry contributed sixty billion in taxes, and pays out fifteen billion in bonuses. In other words, this tax would more than take away all those evil banker bonuses everyone likes to complain about, and up the total tax take by about a third. This is not a subtle tweak, it's a pretty heavy bludgeon.
The effect
Of course, it wouldn't raise twenty billion, because unsurprisingly people's behaviour would adjust to take into account the extra costs. The possibilities I see are:
- Don't trade A lot of trading is happens because it's cheap and convenient. With a tax, they'll trade a lot less.
- Trade elsewhere Or you just trade in another region. This means we gain no tax, and drive a lot of business away from London. Business that does actually raise a fair amount of tax, and we'll probably lose a pile of services that go with the finance sector.
- Trade differently Banks have a lot of experience arranging transactions to be tax-efficient. Perhaps the trading will move from directly buying and selling things (simple, now tax-inefficient) to derivatives (complex, tax efficient). Not an obvious improvement for people who don't like tricksy banking.
The "don't trade" angle is perhaps worth going into a bit more detail on, for those who don't know the area. When I was working on a precious metals gold trading system, doing a test trade, buying and selling a future for 100oz of gold, worth over $100,000, the bid-offer spread costs came to around $20. In other words, each transaction cost around 0.01% of the nominal value. FX is not exactly dissimilar. Taxing an extra 0.05% is going to strongly discourage trading in such situations.
Just because a transaction isn't necessary doesn't make it a bad idea. Banks like to hedge their transactions - they want to get rid of the risk associated with their positions, so that if prices move they don't end up losing big piles of money (yes, I know, they may not always be good at this). However, they don't hedge freely, because hedging costs money. If you up the transaction costs, hedging will cost more and it'll be done less. Banks will hedge less and take more risk. Or they'll keep hedging, but pass the costs on to their customers. It's not great, either way.
The intention
Finally, what's the point of this tax? I don't think it's really to raise money. It wouldn't raise anything like the suggested amount, due to the reasons above. It's also a very distorting tax, which will affect particular kinds of banking more than others.
Indeed, it's so distorting that it's either put together by an idiot, or it's intended to target a particular sector.
The sector that would be affected is the "flow" sector - the simplest, most straightforward products. The sale of complex derivatives such as the mortgage CDOs blamed for the credit crunch, which are much less liquid, with much bigger bid-offer spreads would not be affected by this rule. If it's a reaction to financial meltdown, it makes no sense.
Anyway, let's go with the "bad bankers" narrative, and assume that there are some people who need to have their lives made more difficult. Who is problematic in "flow"? I can see two sets of targets - bad traders and high-frequency traders.
The bad traders keep getting huge fines from the regulators. Fines and jail for wrong-doers seem the way to go here. Blanket taxing everyone involved is hardly an incentive for those who aren't crooked!
The other lot are high-frequency traders, who trade a large volume on tiny, tiny margins. They would be hit extremely hard. They're not actually bankers. They tend to be fairly small companies, operating with their own capital. The main objection is that by being faster than everyone else, they're taking their money away. However, they do seem to have reduced spreads and made the markets more liquid for small traders (i.e. retail customers). HFT basically takes money from the big players by doing what they traditionally did (have an information advantage over everyone else). So far, so meh.
What are the objections? It's socially useless? Candy Crush Saga is probably a bigger waste of time. Anyway. It's an unfair advantage? In the grand scheme of things, the resources required are not huge, and it's a very competitive area.
Let's say it's deemed bad. A Tobin tax is still not a clear winner. The big banks and institutional investors don't like HFT either. Surely they can find a way to deal with HFT? Why, yes! There are dark pools for large trades, exchanges with randomized timing to reduce latency advantages, etc. The problem with HFT may not be that they trade too much, but place too many (unfilled) orders, so you can cap the order to fill ratio. All these things can be fixed in a more targeted manner by adjusting the market mechanism. No tax needed.
So what would I do?
I don't know, as I'm not sure what the aim is. If you want to deal with the problems of flow trading, there are better ways. If you want to deal with problems outside flow trading, there are ways that are actually relevant. If you want to raise more taxes, you can try to increase the tax rates in less distorting ways, or perhaps actually reduce the opportunities for tax avoidance, and clamp down on the "borderline" tax behaviour across the whole of big business. If you want to "fix" banking post-2008, you've got to balance what you want. Extracting large amounts of money is incompatible with making the banks build up large reserves. Getting the banks to lend is incompatible with reducing the risk they take. Taxing banks heavily may not actually be very sensible if you own large chunks of them. If you don't like bankers' pay, regulate it (there are guaranteed to be unintended consquences).
In all cases, "Let's have a transaction tax" sounds suspiciously like "We must do something, this is something, let's do it".
Posted 2015-05-24.
Crowd-sourcing and the Wisdom of Crowds
The Wisdom of Crowds makes some good points about how and when a large number of people can do things better than experts. Crowdsourcing often refers to splitting work across a large number of people. However, what I occasionally see is a "crowd-based" problem-solving approach which is... not really.
For example, if you have a difficult problem, you might shove it out to the crowd. A fan of crowds might say the Netflix Prize was solved that way. However, in that sort of case, it isn't the crowd solving it, it's some bright people. You've just given the problem to some bright people, and a bunch of normal people.
In other words, crowd-sourcing like this is not really about problem-solving, it's about problem-routing - effectively packet-switching problems towards the appropriate experts, even if you don't know who they are. You feed the problem into the social graph and hope it is forwarded to an appropriate destination.
Sometimes, a crowd really is only as wise as its wisest members, but in a large crowd that can still be pretty darn wise.
Posted 2015-05-21.
The Internet is Street Art
I found this note in a file simply saying "The Internet is Street Art". I vaguely remember it from a couple of years ago when I went to Covent Garden, and saw some street performance.
My understanding of street performance, gleaned from limited experience of places like Covent Garden and the Edinburgh Fringe, is that you get in the way of people and show off. Well, it's more than that, it's moderate talent, the ability to manipulate a crowd to create a "people join the crowd to see what the crowd's for" effect, and a willingness to get in the way of those not (yet) interested. The cost of entry as a spectator is nothing, except your attention, and you're probably underestimating the value of that.
And in so many ways, this is the web. It's basically about going viral and getting a crowd. Quality is not the ultimate concern, and the only price is free. And fundamentally, the idea is to get in the way of passers-by.
I don't really like street performance. *sigh*
Posted 2015-05-21.
Linux 1.0 kernel source reading - 7: fs/exec.c and friends
For my first foray into the "fs" directory, I thought I'd try something relatively loosely coupled to the file system, and more to the rest of the kernel I've been reading: The "exec" infrastructure.
exec.c starts with various utility functions whose context will have to arrive later. Bottom-up code isn't always the easiest to understand!
It's kind of strange that "flush_old_exec" doesn't explicitly share code with "sys_exit", as they're both freeing a number of process resources. It's not exactly "Don't Repeat Yourself". (If I were designing this, in a slightly more high-level, OO and RAII kind of way, I'd separate out the structures representing the bits of process that survivce across an "exec" call, and those that don't. On "exec", I'd tear down one structure, on "exit" both.)
Mostly, though, this is straightforward code, and shows how simple the a.out format is!
binfmt_elf.c ELF is more complicated, shock. Probably best read with a copy of the ELF standard. Instead, I'll skim. "/* Now use mmap to map the library into memory. */" comment appears to be in the wrong place, after the work is done!
The interpreter-loading stuff was, unsurprisingly, a bit obscure until I read up on PT_INTERP. It still feels odd having a.out-loading code in the middle of the ELF code, and does rather seem as if there's redundancy in the code.
There are lots of long functions. It might be nice to break them into short functions with well-defined purposes. The overloaded returning of error codes and success values is a bit painful, although I'm not sure there's a pretty alternative in vanilla C.
binfmt_coff.cis written by some other person. Heavily commented, which is nice, but the comments starting in column 0 inside functions make it difficult to see where functions start and end! It refers to "coff.h", which demonstrates a consistent inability to spell "O'Reilly". "load_object" is a 450 line function? Really?
It looks like there's a bug in reading the sections - if there's a badly-aligned section, then a good one, the status code is overwritten and it'll ignore the bad alignment, I think. It probably checks again later, though. There are odd error messages on strange section counts, too, and the continual conditioning on status suggests that "goto"-based error handling may not be that bad after all!
Having said all that, the heavy commenting makes this file pretty readable.
Library-loading is much easier for COFF than ELF. If a COFF header asks to pull in a shared library, rather than execute a loader, it just uses "sys_uselib". This is presumably rather less flexible than the ELF approach, but makes for much simpler code!
Bonus 1: filesystems.c is simply a (ifdef-configured) registry of the known filesystem types.
Bonus 2: file_table.c manages the circular list of all files. For some reason, it mixes in unused file entries with the allocated ones, and generally seems slightly naff code if you ask me. Maybe reading other source will make this clearer?
Posted 2015-05-20.
Linux 1.0 kernel source reading - 6: IBCS and IPC
"IBCS" turns out to be nothing more than a "NYI" stub. And after all the iBCS compatibility stuff in signal handling!
ipc/util.c is the main entry point for sysv ipc. There's a single syscall with a switch statement. sysv ipc support is configurable, so there's an ifdef to switch to dummy code for the disbled case.
ipc/sem.c handles semaphores. The need for sem_lock and IPC_NOID seems odd to me, why not kmalloc first before fiddling a shared structure? "sys_semctl" is ugly (sequence of switches on the same command is odd). The code doesn't quite feel the usual standard of the rest of kernel.
ipc/msg.c - message queues. The business of rechecking the entry's id in "sys_msgsend" makes me nervous. It feels race-condition-like, although it probably really is a valid race condition that meets the expected interface. Much of the code is copy and paste of sem.c. Not quite sure if this is repetition is bad style or just the faff of doing this in C.
ipc/shm.c - shared memory. Again, some shared infrastructure. "shm_map" runs off the actual page table, rather than the mappings structure, which seems inefficient. It also maps in the new top-level pages while checking the existing mappings. If shm_map fails due to a clash, you'll have a pile of empty top-level tables, which is mildly naff.
One mildly tricky (and uncommented) bit of code: As far as I can tell, swapping shared memory works by getting the reference count down to 1, which represents the reference count from the shared memory object itself (the other references being from it being mapped into processes). At that point, the page can be swapped.
Overall, I was a little underwhelmed by the quality of the IPC code...
Posted 2015-05-16.
Learning modern web technology
It occurred to me that if I am to work for a web firm I should really know some web technology. My knowledge of the web was extremely out-of-date and patchy, so I thought it time to make it up-to-date and patchy. The aim wasn't to learn all the latest trendy technologies, but more what's been the backbone for a while.
The web used to be a horrible mess, but with the triumvirate HTML5, CSS and Javscript, plus modern browsers, things are a lot neater and more pleasant. To learn, I did a pile of courses on codecademy. This was rather neat as I didn't only learn a bit of modern HTML, CSS and JS, but I also got pointed at Boostrap and jQuery. I guess you can say technology is mature when it's got helper libraries on top of it! I understood the existence of JS helpers, but CSS helpers were a bit of a surprise.
Anyway, the existence of these libraries explained something of a mystery to me: Why so many websites have such similarity in style, beyond the demands of fashion. Well, they're all using the same libraries. Also, I got to find out that the basic use of jQuery is not to do with querying, but for putting animations and effects on your web pages.
It also reminds me how conventional web pages are looking now. I remember "The web is a new medium! The old rules don't apply!". And now, the web looks like magazines. Ho hum. Anyway, my website's been updated to look like all the others, using the same libraries as everyone else. It's good practice, right?
One of the things I found interesting about Javascript was quite how heavily anonymous functions are used for callbacks and the like. It's almost like continuation-passing. On the one hand, it's interesting to see bits of functional programming becoming quite so mainstream. On the other side, it shows how clunky things can be without the right abstractions. Partial application is a pain, and you can't e.g. use monads or whatever to abstract away the sequencing of callbacks.
Finally, I picked up AngularJS. I must admit, I feel somewhat ambivalent about it. For dynamic data, you've got to do things on the client-side. However, it seems to go a bit far - the codecademy tutorials encourage you to do things on the client-side that could have been done on the server-side. This seems inefficient and an unpleasant move away from the underlying document-centric view of the web. On the other hand, it's good for creating dynamic sites quickly and flexibly, without having to build server-side and client-side frameworks in tandem.
I can see this kind of mindset leading to painful mobile apps. As you can make a fairly fully-featured UI in a web browser, complete with JS implementation, why not just use that for the backbone of your app? Unfortunately, mobile phones don't have the spec of desktops. Well... I guess Moore's law is going to sort my objection out sooner or later, and you can have pretty and fast apps on your phone, at the expense of battery life.
Mostly, though, I can see the use in Angular. With modern hardware and the kind of web apps people are developing, efficient technology is beaten by RAD technology 95% of the time.
Posted 2015-05-08.
Julia sets with continuous deformation
I've been playing with HTML5 canvases and Javascript to create an in-browser Mandelbrot/Julia set viewer which can show the Julia set iteration function as a continuous deformation. It's something I've been thinking of for a while, but it's rather nice to implement it!
Without further ado here is my Mandelbrot/Julia set toy.
Posted 2015-05-07.
Getting rid of some books
I love books. I very rarely get rid of books. I have actually kept the worst books I've read, as a reminder of how poor they were. So, it's unusual for me to get rid of books, but now I'm getting rid of a few. To mark the occasion and remind me of them, I'm semi-reviewing them!
O'Reilly Make There was a point when I'd assume that any O'Reilly book on a subject was the bees' knees. Those were the days when standard utilities weren't documented every which way all over the internet. You might have a man page or info files for the GNU version, but it wasn't particularly approachable. Certainly no Stack Overflow. So, I bought a book on "make". It was mediocre at the time, and useless now.
O'Reilly Lex and Yacc Pretty much the same story.
Java in a Nutshell On the other hand, this was pretty useful. A quick summary of the Java libraries that could be flicked through quickly was great - online docs tended to be long-winded and difficult to search. Unfortunately, this book only goes to Java 1.1. As the language has grown so much, I expect the latest nutshell might not live up to its name.
Unix in a Nutshell Bought somewhat later, this was not so useful. Unix documentation is pretty thorough, and nutshell-like anyway, so this has less value. There are summaries of things like sh, sed and awk, but that's superseded by the O'Reilly shell scripting book I bought more recently.
Progamming Perl This O'Reilly book is generally deemed to be a classic. I never got into it. My review gives the reasons, but basically Perl is just not the way I think, and now that Perl has lost its favoured status, I'm glad to be rid of it.
A Guide to LaTeX (Kopka and Daly) A not great guide to a not great system. Overall, the output of LaTeX is great, but it really does demonstrate what happens if you fail to separate the mark-up from presentation information from the start, and moreover if (at the TeX level) you create a general-purpose programming language without admitting it and making a proper language of it. I just feel the book really reflects the underlying system, rather than being a disaster in itself. If I'm not writing a proper paper, it's Markdown and MathJax for me right now.
Generic Programming and the STL (Austern) Way back when (PhD days, or before?), I wanted to understand the STL, so I chose this book. Bad choice. The subtitle is "Using and Extending the C++ Standard Template Library", and the key word is Extending. This book is much more about the interfaces and contracts provided by the library, rather than normal usage. For example, the actual containers get 70 pages of documentation for 15 classes, in a 500 page book, right at the back. Perhaps good for language lawyering and actually creating STL extension libraries, but not much use to me otherwise.
The Java Tutorial I previously reviewed this book, and, well, I've read it and I don't think it holds much long-term value for me now.
The Nitpicker's Guide for Classic Trekkers This is a detailed episode guide to the original series of Star Trek. However, over time it has become obvious to me that I fundamentally don't care much for the original series.
Roget's English Thesaurus If the internet breaks, synonyms will not be my greatest worry.
Reverse Dictionary Interestingly enough, this is pretty much a synonym for "thesaurus".
The Bloke's Guide to Pregnancy Reviewed here. Not planning to go through that again! In this area, I would recommend "The Rough Guide to Pregnancy and Birth", followed by "What to Expect - the first year".
Posted 2015-04-28.
Linux 1.0 kernel source reading - 5: Memory management
Over to the "mm/" directory.
kmalloc.c: Hmmmm. Something else that implements kmalloc/kfree. Careful reading of lib/Makefile reveals that lib/malloc.c is not actually compiled, so I guess this is used instead!
I prefer the other implementation. This one has crazy indents and fewer comments. Also, it puts the control block in the page with the data, which means allocation blocks of powers of two don't fit in neatly, and you can't actually allocate large chunks efficiently.
Oh, and it allows a pointless race in the code to allocate from a new page: If there are no blocks available, it constructs a new page, adds it to the list, and then races against anything else to take an item out of that list, complete with code to give up if it loses the race too often. More simply, it could just allocate the chunk from the newly constructed page before hooking the remainder into the pool. Naff design.
And there are other minor stylistic things I don't like.
swap.c: _get_free_page lives here, so it seems a good place to start. In the standard style of C, it's written in a bottom-up fashion, and there isn't high-level explanation comments, so it's a bit of an exercise to work out what it intends to do as we go along.
The basic idea at start of file is to treat swapped-out pages as a specialised resource, with functions to to claim, free, duplicate (increase ref count), etc.
It looks like swapped-out pages get duplicated when they're swapped in... but the pages that actually get paged out are ones that are not already backed by a file, so the paging back in effectively just does a copy-on-write-like step as the page is pulled in.
The next part of the file moves on to the mechanism for trying to swap out pages (which calls into other areas, mildly breaking the layering of abstractions). Then later parts of the file deal with freeing pages (free_page), and getting a page (__get_free_page), kicking off some swapping if necessary. The file concludes with the turning on and off of swap devices and swap files.
memory.c: This file is a chunky one, and the next layer up the abstraction stack. Rather than dealing with the allocation of individual pages (and swapping), it deals with page tables (modulo swapping) and the mapping of ranges of VM.
The "oom" function is commented to send an "untrappable SIGSEGV". The code seems to send a SIGKILL. For some reason, this amused me.
Various functions have heavily duplicate code - "clear_page_tables" vs. "free_page_tables". This reveals the pain of working in a low-level language like C (I'm currently reading On Lisp).
"share_page", to find a page for a VM mapping that can be shared, looks hideously expensive, and the wrong way to do things. VM mappings should know where their pages are, not have to scrape processes! Sharing with buffer cache seems a more pleasant alternative, too (and is perhaps how you should really do this look-up).
The end of this file deals with the page fault handling mechanism, and the basic VM ops structure for a file memory mapping.
mmap.c: This builds memory mapping infrastructure on the above. Mostly works on the VM area linked list, so it's not clear how this is kept in sync with the actual page tables. e.g. munmap partially unmapping an area doesn't actually necessarily update the page table, so partially unmapped areas may actually remain accessible in the address space. Or I could be misreading the code. The fun of maintaining invariants in a low-level language!
vmalloc.c: This one works a little more independently. Its purpose is not explained, but it is evidently to do multi-page kernel memory allocations. It does this by finding free physical pages and assigning virtual addresses to create the needed contiguous memory in virtual address space. It stops physical page fragmentation from being a problem for large kernel allocations. Rather obviously, it assumes that you have a lot more virtual address space than physical RAM, which was certainly the case back in the day. It creates the kernel memory mapping by updating the kernel memory page tables for each process, which seems an inefficient but simple way to do it.
Theoretically, I think I've covered the real core of the system now. Realistically, given "everything is a file" (more or less), I need to read the generic parts of "fs/" to claim I've read the core parts. For example, "exec" is in fs/. Next up, I'll take a brief detour to ipc/ and ibcs/, and then time to tackle fs/.
Posted 2015-04-19.
Recreating the NTK 31337/Elite t-shirt
One of my favourite t-shirts is the old NTK Elite t-shirt. My wife has pointed out it's a bit grubby, and needs replacing. I thought she might just be jealous of a t-shirt I've known longer than her, but I think she does have something of a point.
Having recently experimented successfully with custom t-shirt printing, I thought I could create myself a replacement. And that's what I did. A pixel-based design is fairly easy to copy, although getting the measurements of the wide-open spaces was something of an estimation. I tried to keep in the infelicities of the original design, keeping it as close to the original as possible.
One thing I hadn't realised originally is that the main screen is a simple 256 pixels across, but the strap-line at the bottom isn't on the same resolution (which can be checked simply - there are more than 32 8-pixel letters). In order to keep the whole design as a simple low-resolution image, I rejigged the bottom, squashing a few spaces to fit into a 256-pixel-wide image, and I must admit I'm pretty happy with the result.
The resulting t-shirt, next to the original, for comparison, looks like this:

Overall, I think it looks pretty good. The placement is about right, the colour of the shirt is fine. The image isn't quite as wide as the original. I thought I adjusted the size to match what I measured from the original... perhaps it was slimmed to fit into the bounds of their printing mechanism? Ho hum. In any case, I'm pretty happy with it.
Posted 2015-04-13.
An insight into the mind of a small child, or communications problems
I've been clearing out stuff from my parents', as previously described, and came across a picture I painted when rather small:

I was always rather proud of myself for this painting, but apparently the non-standard colour scheme concerned my parents a little. Why is everything strange colours, when other children were using the colours rather more conventionally? Of course, they never said anything at the time. Neither, of course, did I.
I was just painting so that each colour was used for the same number of edges. In fact, I remember being annoyed as I had the counts matching perfectly, but the teacher told me I needed to paint some more things, and the addition (the swings, I think), made it very difficult to get the counts matching - I couldn't make the extra number of lines required into a multiple of four!
On second thoughts, given what I was trying to do, perhaps my parents were right to worry...
Posted 2015-04-13.
Wrapping up computers and sensible industrial design
I've just spent the weekend moving the last few bits out of my parents' house - just a few odds and ends that never got prioritised (yes, I took my time). This includes a few old computers. I wrapped them up in a bit of bubble-wrap for transport. From this experience, and the fact I want to transport them, and the fact that people often want to stack up a set of computers, reveals a useful design priciple: A computer should be able to lie safely on any face.
You'd have thought this would be obvious. A decent number of machines have their ports on the back recessed in order to meet this point. This is very useful if the ports are mounted directly on the motherboard, where excess pressure on the back can break the whole thing. BNC connectors (as seen on 10Base2, and some video connectors) are particularly bad, as they're quite deep and stick out far.
Anyway, the HP 9000/340 loses badly, with a full 4 BNC connectors sticking way out of the back of the machine, completely unprotected. *sigh*
Posted 2015-04-13.
Some silly custom t-shirts
I'll soon be moving jobs. The company I'm going to has a looser dress code than my current employer, which means I'm going to need a few more t-shirts. Custom-printed t-shirts are now really quite cheap (yay, computers!), so it gave me the opportunity to get myself a couple of custom designs. For some reason, this makes me surprisingly happy.

The first design is the character "Head" from the Spectrum game "Head Over Heels", which you may know I'm something of a fan of. I always need more monochromatic pixel art in my life. I've ended up using this as my avatar on Github and a couple of other places, since a tiny icon of some white bloke is not exactly highly-distinguishable (roll on diversity in IT, please).

The other one is something rather more obscure. You've probably seen those designer-ish t-shirts with "Helvetica" written on them in nice, friendly letters. This t-shirt is just like that, except "Helvetica" is written in Arial, the cheap Helvetica knock-off that's infiltrated everywhere. Happily, it looks a little bit naff and knock-off-y, which is just what I wanted.
The company that printed them for me has given me a money-off voucher, so I'm very tempted to do a few more...
Posted 2015-04-05.
More craft stuff: Basic sewing machine usage
So, sewing. I want to make a few bits and pieces that involve the use of a sewing machine. I still find the mechanism behind sewing machines utterly nutty, but fortunately you don't have to think about the mechanical magic while using them.
The first thing I did was try to knock up a couple of shapes to practise "invisible finishing", which I'm quite frankly rubbish at:

Bearing in mind I've tried to put the best side to the camera, you can see it's not great! I tried to construct a square (not terribly straight edges) and a tetrahedron (a slightly better shape, but the finishing in the corners is nafff.
Then, a very simple project: A keyboard bag. Given the silly amount of time I spent working on my DIY keyboard, it seems to make sense to keep it safe when transporting it. So, I constructed a keyboard bag. No invisible finishing, no fancy lining, just a piece of fabric sewn up two sides with a bunch of fiddling at the top for a draw-string:

It does the job, and I'm pretty happy with it. One thing I've learnt with this, as with most craft/making stuff is "don't make mistakes". Catching bugs early in programming is vital to good productivity. When you deal with the real world, it's even worse. Undoing physical mistakes can vary from "difficult" to "impossible", and certainly slows you down. Much easier to spend a bit of time sewing the right line than to tediously unpick a piece of bad sewing. In that respect, computers and "undo" have spoilt me.
Posted 2015-04-01.
Linux 1.0 kernel source reading - 4: The rest of kernel/
This time, I'm polishing off the rest of the "kernel/" directory. It's a short review of a few relatively long files (not long in absolute terms, fortunately).
sys.c: vm86 is messy. I'm starting to wonder if the whole threading thing being written as a co-routine or continuation-based abstraction could hide the grim, but I'm not convinced. A lot of this file consists of very boring system calls.
fork.c: Quite fun! How to duplicate all the things you need to create an identical process. Some parts, that depend upon fs and mm aren't clear yet, as I need to read the code, but the intuition is pretty clear. I see this common pattern with C code that I get twitchy about invariants being held that would be managed wonderfully with well-encapsulated objects and RAII.
signal.c: Oh look, yet another structure to hold all the register state! This is used when saving state on the stack during signals for iBCS compatibility, it seems. The manipulation of the user stack, with the use of the "sigreturn" system call at the end of the signal handler is interesting, as is the setting up of a chain of signal handlers in a single go.
exit.c: Almost a misnomer - there's plenty of code that isn't pure exit code, as it segues to exit code handling, wait, process groups, and other signal-related stuff. Again, RAII would make safe clean-up a lot easier IMHO.
ptrace.c: Handles process debugging stuff, and is a little odd and encapsulation-breaking - it manually traverses the page table, for example.
Posted 2015-04-01.